
Diffusion Transformers (DiTs) have revolutionized image and video generation enabling stunningly realistic outputs in systems like Stable Diffusion and Imagen. However, despite innovations in transformer architectures and training methods, one crucial element of the diffusion pipeline has remained largely stagnant- the autoencoder that defines the latent space.
Most current diffusion models still depend on Variational Autoencoders (VAEs) designed primarily for pixel reconstruction and heavy compression. While VAEs have enabled the concept of latent diffusion, they also introduce bottlenecks limited latent dimensionality outdated convolutional backbones and weak semantic representation.
A recent paper, “Diffusion Transformers with Representation Autoencoders (RAEs)” by researchers at New York University offers a groundbreaking alternative. It reimagines the autoencoder not as a compression tool but as a semantic representation foundation for generative modeling.
By replacing the VAE with a Representation Autoencoder (RAE) built on pretrained models like DINOv2, MAE or SigLIP, the authors achieve faster training, richer representations and state-of-the-art generation quality. This marks a fundamental evolution in how diffusion transformers learn to synthesize and understand images.
The Problem: VAEs Are Limiting Diffusion Models
In latent diffusion systems, VAEs map high-resolution images into a compact latent space often with only a few channels. This process improves computational efficiency but at a major cost: information loss.
Traditional VAEs, like those used in Stable Diffusion (SD-VAE), focus purely on pixel reconstruction. They compress visual information so heavily that the resulting latent codes capture texture but miss global structure and semantics. In practice, this means diffusion transformers must learn to generate high-fidelity content from low-capacity latents leading to slow convergence and limited generalization.
Furthermore, most VAEs rely on convolutional architectures. Diffusion Transformers, in contrast use Vision Transformer (ViT) backbones that operate on tokens. The mismatch between convolutional encoders and tokenized transformers introduces inefficiencies and architectural incompatibilities.
In short:
- VAEs compress too much → lose semantic richness.
- Convolutional encoders → poor synergy with transformer architectures.
- Low-dimensional latents → slow convergence and weak generative performance.
The Solution: Representation Autoencoders (RAEs)
The Representation Autoencoder (RAE) is a new class of autoencoder that turns this paradigm on its head. Instead of training a new encoder from scratch, RAEs reuse frozen pretrained representation encoders such as DINOv2, SigLIP or MAE – models that already learn robust, semantically structured visual features through large-scale self-supervised or multimodal training.
A lightweight ViT-based decoder is then trained to reconstruct the image from these rich representations. The result is a latent space that is:
- High-dimensional – retains texture and semantics simultaneously.
- Semantically meaningful – aligns with human-interpretable visual features.
- Transformer-compatible – natively tokenized for ViT and DiT architectures.
This simple but elegant shift results in significantly higher quality and efficiency.
For example, in ImageNet tests, RAEs achieved an rFID of 0.49 compared to 0.62 for SD-VAE while requiring 3–6× less compute (GFLOPs) for both encoding and decoding.
Training Diffusion Transformers in RAE Latent Space
Adopting RAEs introduces a challenge: diffusion models were designed for small, low-dimensional latents. To operate effectively in the higher-dimensional RAE space, Zheng et al. introduced three key innovations.
1. Width Scaling for High-Dimensional Tokens
The authors show that a diffusion transformer must have a hidden width equal to or greater than the token dimension of the RAE. If the model’s width (e.g., 384) is smaller than the token dimension (e.g., 768 in DINOv2-B), it cannot fit even a single image properly leading to poor learning or total collapse.
When width ≥ token dimension, however, the model converges cleanly, generating realistic samples and achieving low training loss. This finding challenges the assumption that generative models always need compact latents; in fact high-dimensional representations can accelerate convergence when modeled correctly.
2. Dimension-Dependent Noise Scheduling
Diffusion models progressively add noise during training, but existing noise schedules were tuned for pixel or low-dimensional latent inputs. In high-dimensional RAEs, this causes under-corruption, making learning unstable.
To fix this, the authors introduce a dimension-aware noise shift:
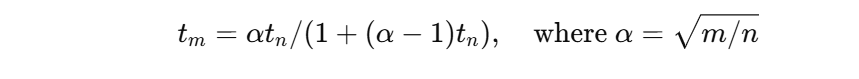
Here, (m) represents the effective latent dimension. This ensures consistent corruption levels across different token sizes.
The result: generation FID drops dramatically from 23.08 to 4.81 demonstrating that correct noise scaling is crucial for stable high-dimensional diffusion.
3. Noise-Augmented Decoding
Because RAEs decode from discrete representations, the decoder can struggle with noisy latent outputs from diffusion. To address this, the team adds Gaussian noise augmentation during decoder training , teaching the model to handle slight distribution shifts at inference time.
This reduces generation FID further (from 4.81 to 4.28), improving robustness while maintaining reconstruction fidelity.
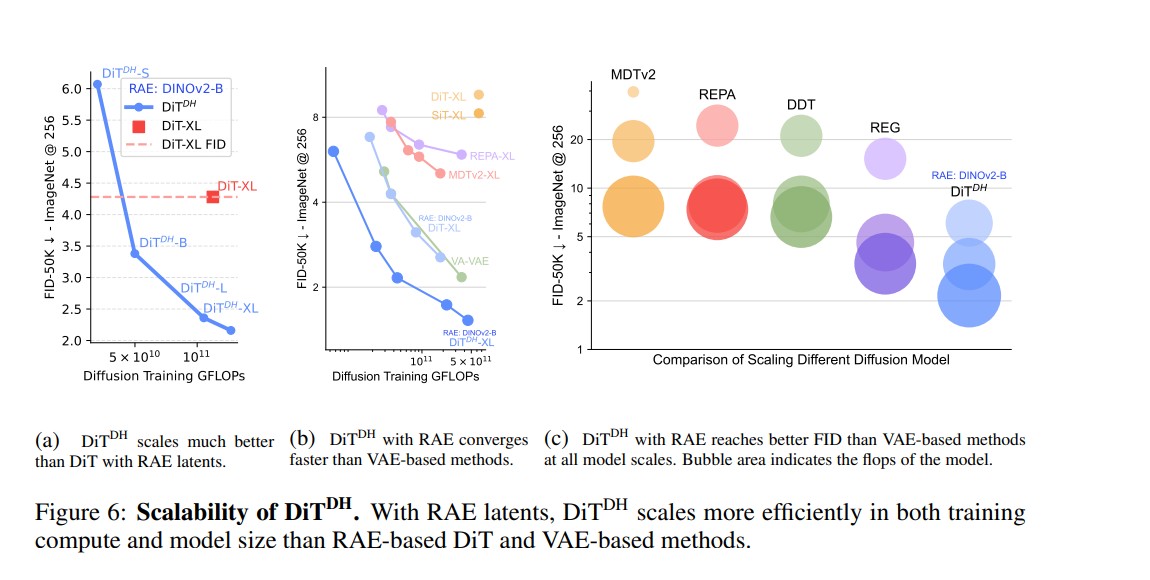
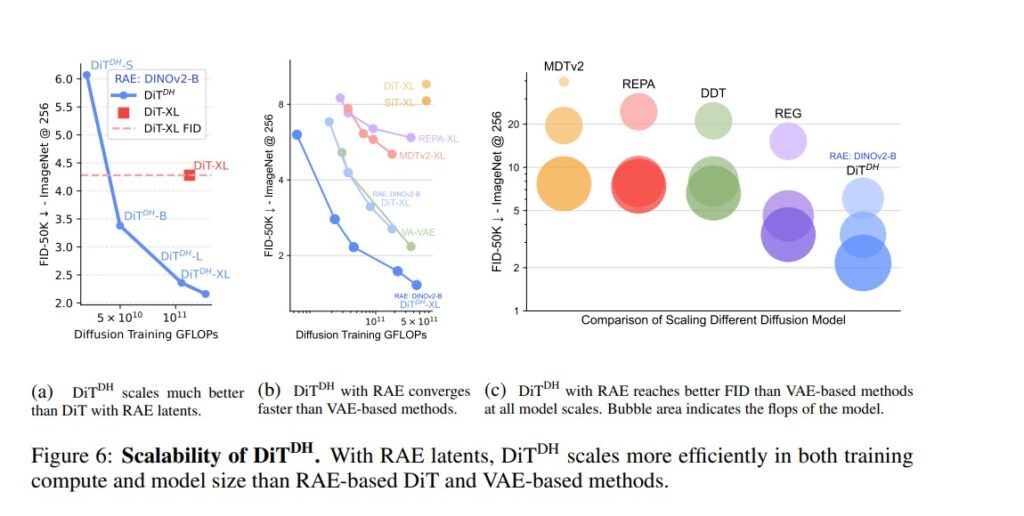
Introducing DiTDH: A Scalable Diffusion Head
Scaling up DiTs to handle high-dimensional latents can become prohibitively expensive. To overcome this, the researchers propose DiTDH – a Diffusion Transformer with a Wide Denoising Head.
Instead of increasing the entire backbone’s width, DiTDH attaches a shallow but wide transformer head to the base model. This widens the diffusion capacity efficiently without quadratic growth in compute.
Empirical results are impressive:
- 1.51 FID at 256×256 (no guidance)
- 1.13 FID at 256×256 and 512×512 (with guidance)
These numbers surpass all previous VAE-based and alignment-based approaches such as REPA, DDT and VA-VAE.
At the same time, DiTDH trains up to 47× faster than SiT and 16× faster than REPA — a major leap in training efficiency for diffusion transformers.
Performance and Scalability
On ImageNet, RAE-based diffusion models outperform prior architectures across multiple metrics:
| Model | Type | FID (256×256) ↓ | FID (512×512) ↓ |
|---|---|---|---|
| SD-VAE (Baseline) | VAE | 7.13 | 3.04 |
| REPA-XL | Alignment | 1.70 | 1.29 |
| RAE-DiTDH-XL (Ours) | RAE | 1.51 | 1.13 |
Even more striking is the scalability: by allowing the decoder to handle upsampling, DiTDH can generate 512×512 outputs using 256×256 latents achieving competitive quality at ¼ the compute cost.
Why RAEs Matter for the Future of Generative AI ?
Representation Autoencoders are more than an architectural tweak , they represent a new philosophy for bridging representation learning and generative modeling.
Instead of separating “understanding” (encoders like DINO or MAE) and “generation” (diffusion models), RAEs unify them in a shared latent space that is both semantically meaningful and generatively expressive.
Key Advantages of RAEs
- Richer latent representations: pretrained encoders carry semantic knowledge learned from billions of images.
- Faster convergence: high-dimensional tokens make the diffusion process smoother.
- Architectural simplicity: no extra alignment losses or complex training objectives.
- Superior scalability: efficient training across resolutions and model sizes.
In essence, RAEs turn latent diffusion into representation-aware generation, moving diffusion models closer to human-like visual understanding.
Conclusion
Diffusion Transformers with Representation Autoencoders redefine how generative models learn to see and synthesize the world. By replacing VAEs with pretrained semantic encoders and introducing smart diffusion adjustments, RAEs unlock both semantic depth and visual fidelity achieving state-of-the-art results with less compute.
As we move toward foundation-scale generative systems, RAEs could become the new standard for training efficient, scalable and semantically grounded diffusion transformers bridging the gap between representation learning and image generation.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- LLaMAX2 by Nanjing University, HKU, CMU & Shanghai AI Lab: A Breakthrough in Translation-Enhanced Reasoning Models
- Granite-Speech-3.3-8B: IBM’s Next-Gen Speech-Language Model for Enterprise AI
- Thinking with Camera 2.0: A Powerful Multimodal Model for Camera-Centric Understanding and Generation
- Jio AI Classroom: Learn Artificial Intelligence for Free with Jio Institute & JioPC App
- Unsloth AI: The Game-Changer for Efficient 2*Faster LLM Fine-Tuning and Reinforcement Learning
4 thoughts on “Diffusion Transformers with Representation Autoencoders (RAE): The Next Leap in Generative AI”