
AEPO (Agentic Entropy-Balanced Policy Optimization) represents a major advancement in the evolution of Agentic Reinforcement Learning (RL). As large language models (LLMs) increasingly act as autonomous web agents – searching, reasoning and interacting with tools – the need for balanced exploration and stability has become crucial. Traditional RL methods often rely heavily on entropy to encourage exploration but excessive entropy can cause instability, inefficient tool use and even training collapse. AEPO directly addresses these issues by introducing a balanced mechanism that intelligently manages entropy throughout the learning process.
At its core, it combines a Dynamic Entropy-Balanced Rollout with an Entropy-Balanced Policy Optimization strategy. This dual-phase approach enables models to explore high-uncertainty reasoning paths without losing stability or wasting computational resources. By penalizing redundant exploration and preserving meaningful gradients from high-entropy tokens, it allows AI agents to learn more efficiently and generalize better across multi-turn web reasoning tasks. The result is a smarter, faster and more reliable framework for training next-generation AI systems capable of deep information seeking and autonomous decision-making.

Read the full paper on arXiv
Explore the official GitHub repository
The Problem with Traditional Agentic RL
In Agentic Reinforcement Learning (Agentic RL), models interact with dynamic environments such as search engines, browsers or code executors. While entropy-driven exploration helps the model learn new strategies too much entropy leads to two critical problems:
- High-Entropy Rollout Collapse – The agent excessively branches out along uncertain trajectories, depleting computational resources on repetitive or low-value paths.
- High-Entropy Token Gradient Clipping – During the policy update phase, gradients from high-entropy tokens are over-clipped hindering the model’s ability to learn from exploratory behaviors.
These issues cause instability in long-horizon reasoning and reduce the effectiveness of web agents, particularly in multi-turn interactions like complex searches or tool-based reasoning.
Introducing AEPO: A Balanced Approach to Entropy in RL
Agentic Entropy-Balanced Policy Optimization (AEPO) introduces an elegant dual-phase solution to tackle these challenges:
1. Dynamic Entropy-Balanced Rollout
AEPO implements a pre-monitoring mechanism that adaptively distributes exploration resources between global and branch-level rollouts. It evaluates token-level entropy to determine how uncertain a step is and then penalizes consecutive high-entropy tool calls to prevent over-branching.
This design ensures:
- More diverse trajectory sampling
- Balanced computational resource allocation
- Reduced risk of rollout collapse
2. Entropy-Balanced Policy Optimization
Instead of uniformly clipping gradients, AEPO introduces a stop-gradient mechanism that preserves gradients of high-entropy tokens during backpropagation. It also includes entropy-aware advantage estimation allowing the model to prioritize learning from uncertain but informative steps.
This leads to:
- Smoother gradient flow
- Greater stability in training
- Improved exploration efficiency
How AEPO Outperforms Other RL Methods ?
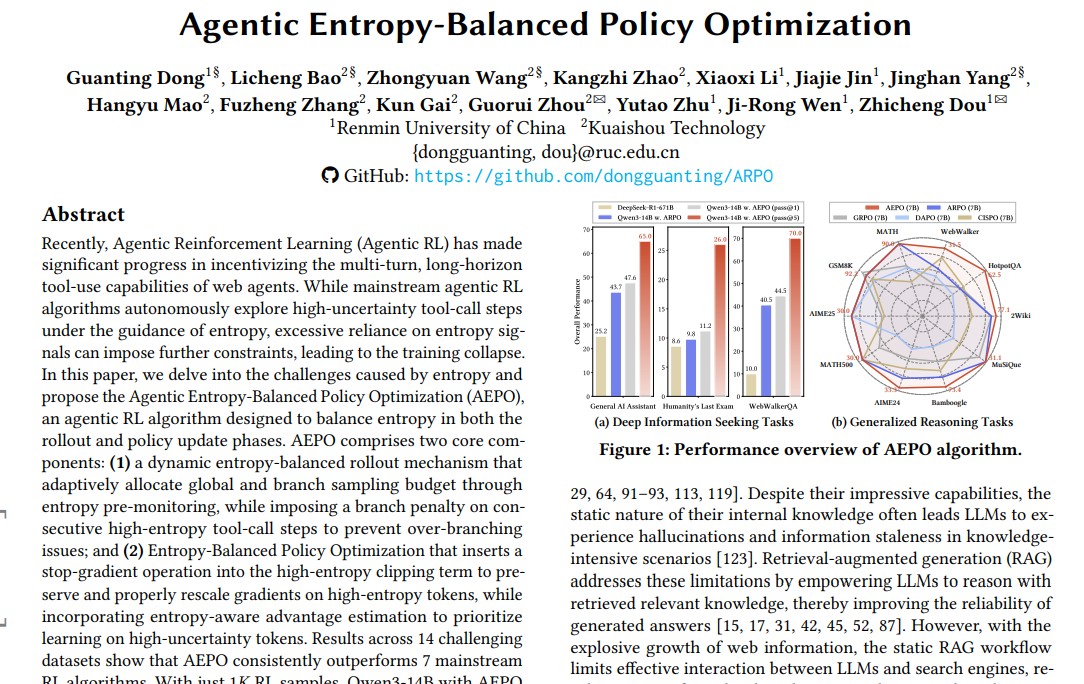
The researchers benchmarked AEPO against seven mainstream RL algorithms, including GRPO, ARPO and GPPO across 14 reasoning and web-search datasets such as GAIA, Humanity’s Last Exam and WebWalkerQA.
Key Results
- With only 1K RL samples, Qwen3-14B + AEPO achieved:
- 47.6% on GAIA (Pass@1)
- 11.2% on Humanity’s Last Exam
- 43.0% on WebWalkerQA
- On broader reasoning tasks, AEPO outperformed traditional RL methods by up to 5% in accuracy while maintaining higher rollout diversity.
Notably, AEPO also reduced tool calls by nearly 50% proving that intelligent entropy control not only improves performance but also cuts computational costs.
Why Entropy Balancing Matters in Web Agent Training ?
Entropy represents uncertainty. In web agent reinforcement learning, it signals when a model is unsure about the next tool call or reasoning step. While earlier algorithms like ARPO used entropy to trigger exploration, they lacked a mechanism to control how much exploration is appropriate.
AEPO’s innovation lies in treating entropy not as a one-way signal but as a dynamic balancing factor.
By adapting entropy budgets based on contextual uncertainty, AEPO enables the agent to:
- Explore deeper when uncertainty is valuable
- Converge faster when the policy becomes confident
- Maintain stability throughout multi-turn reasoning
In essence, AEPO transforms entropy from a risk into a resource fostering scalable self-improving agents.
Applications and Future Directions
AEPO opens the door to a new generation of general-purpose AI agents capable of robust, autonomous reasoning across domains.
Potential applications include:
- AI research assistants that interact with web APIs and databases to synthesize knowledge
- Autonomous data analysts capable of querying live information for decision-making
- Multi-tool AI systems for code execution, scientific discovery and academic search
Future research could explore AEPO’s integration with multi-modal models (text + vision) and continual learning frameworks expanding its reach beyond web-based agents into robotics, software automation and intelligent tutoring systems.
AEPO vs. ARPO: The Evolution of Agentic RL
| Feature | ARPO | AEPO |
|---|---|---|
| Rollout Strategy | Entropy-guided branching | Dynamic entropy-balanced rollout |
| Policy Update | Uniform gradient clipping | Stop-gradient entropy-balanced optimization |
| Exploration Efficiency | High but unstable | High and stable |
| Tool-Call Usage | Redundant | Efficient and adaptive |
| Overall Performance | Strong baseline | Consistently superior across benchmarks |
AEPO represents a second-generation Agentic RL approach – one that values not only exploration but balance, efficiency and control.
Conclusion
The launch of Agentic Entropy-Balanced Policy Optimization (AEPO) marks a significant milestone in the evolution of autonomous reasoning systems. By intelligently balancing entropy during rollout and policy updates, AEPO enables AI agents to explore effectively, learn efficiently and perform consistently.
As web agents continue to define the future of intelligent automation, AEPO stands as a cornerstone algorithm bridging the gap between high-entropy creativity and disciplined learning.
In the era of intelligent web agents, balance is power and AEPO achieves it with scientific precision.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- NVIDIA, MIT, HKU and Tsinghua University Introduce QeRL: A Powerful Quantum Leap in Reinforcement Learning for LLMs
- MinerU2.5 by Shanghai AI Lab, Peking University & Shanghai Jiao Tong University Sets New Standard for AI-Powered Document Parsing
- Diffusion Transformers with Representation Autoencoders (RAE): The Next Leap in Generative AI
- LLaMAX2 by Nanjing University, HKU, CMU & Shanghai AI Lab: A Breakthrough in Translation-Enhanced Reasoning Models
- Granite-Speech-3.3-8B: IBM’s Next-Gen Speech-Language Model for Enterprise AI
References
Read the research paper on arXiv
Explore the AEPO implementation on GitHub
4 thoughts on “Agentic Entropy-Balanced Policy Optimization (AEPO): Balancing Exploration and Stability in Reinforcement Learning for Web Agents”