
In the rapidly evolving landscape of multimodal AI, Qwen3-VL-8B-Instruct stands out as a groundbreaking leap forward. Developed by Qwen, this model represents the most advanced vision-language (VL) system in the Qwen series to date. As artificial intelligence continues to bridge the gap between text and vision, Qwen3-VL-8B-Instruct emerges as a powerful engine capable of comprehending text, images and videos in a unified human-like manner.
Built upon years of research and development, Qwen3-VL-8B-Instruct introduces an entirely new level of spatial awareness, reasoning depth, long-context understanding and cross-modal integration. From processing lengthy documents and understanding detailed scenes to generating complex outputs like code, diagrams or narratives, this model embodies the next step in multimodal intelligence.
Whether you are developing AI agents, building visual understanding systems, or working on creative applications like UI automation and video reasoning, Qwen3-VL-8B-Instruct delivers the versatility and precision required to push innovation further.
What is Qwen3-VL-8B-Instruct?
Qwen3-VL-8B-Instruct is an image-text-to-text model designed to understand, reason and generate content across visual and textual modalities. It’s a product of the Qwen3 series which has become known for its superior large language and vision-language architectures.
This specific version, the 8B-Instruct model, features an 8-billion parameter dense architecture (with MoE — Mixture of Experts — variants available) and delivers top-tier performance in multimodal reasoning, spatial analysis and long-context comprehension.
Qwen3-VL-8B-Instruct isn’t just about reading or describing images — it’s about understanding the world visually and linguistically. The model can interpret complex visual scenes, identify relationships between objects, parse documents, analyze videos and even generate structured outputs like code or webpage layouts directly from visual input.
Key Features
Qwen3-VL brings a series of groundbreaking innovations that redefine how AI interprets multimodal data. Let’s explore its most significant advancements:
1. Visual Agent Capabilities
Qwen3-VL-8B-Instruct introduces a “Visual Agent” mode, capable of interacting with graphical user interfaces (GUIs) on desktops and mobile devices. It can recognize buttons, menus and input fields; understand their purposes; and autonomously execute tasks. This makes it ideal for AI-driven UI automation, software testing and digital assistant applications.
2. Visual Coding Boost
The model can generate HTML, CSS, JavaScript, and Draw.io diagrams directly from images or videos. Developers can use it to convert design mockups into functional web code or to interpret architectural sketches into structured layouts. This feature bridges design and development with an unprecedented level of automation.
3. Advanced Spatial Perception
With enhanced 2D and emerging 3D grounding, Qwen3-VL demonstrates a sophisticated understanding of spatial relationships, object positions and occlusions. It can infer viewpoints, distances and motion within visual scenes crucial for robotics, augmented reality (AR) and autonomous systems.
4. Long Context and Video Understanding
Qwen3-VL boasts a native 256K context window, expandable to 1 million tokens allowing it to handle entire books, lengthy documents and hours-long video content with complete recall and temporal reasoning. It introduces text–timestamp alignment enabling precise understanding of event sequences in videos.
5. Enhanced Multimodal Reasoning
Unlike earlier models, Qwen3-VL-8B-Instruct excels in STEM and mathematical reasoning. It performs causal analysis, logical inference and evidence-based problem-solving across both text and visuals, making it a valuable tool for educational applications, research and data analysis.
6. Upgraded Visual Recognition
Trained on a massive and diverse dataset, the model achieves exceptional visual coverage, accurately identifying celebrities, landmarks, products, plants, animals, and even anime characters. Its recognition capabilities are among the broadest in any open vision-language model.
7. Expanded Multilingual OCR
It’s OCR engine now supports 32 languages (up from 19), excelling even under low light, blur and complex document layouts. It handles ancient scripts, rare characters and domain-specific jargon making it suitable for historical text digitization and global enterprise document processing.
8. Seamless Text–Vision Fusion
It achieves text understanding on par with top-tier LLMs while integrating it seamlessly with vision comprehension. This results in lossless, unified multimodal reasoning — the AI can read, see and think holistically.
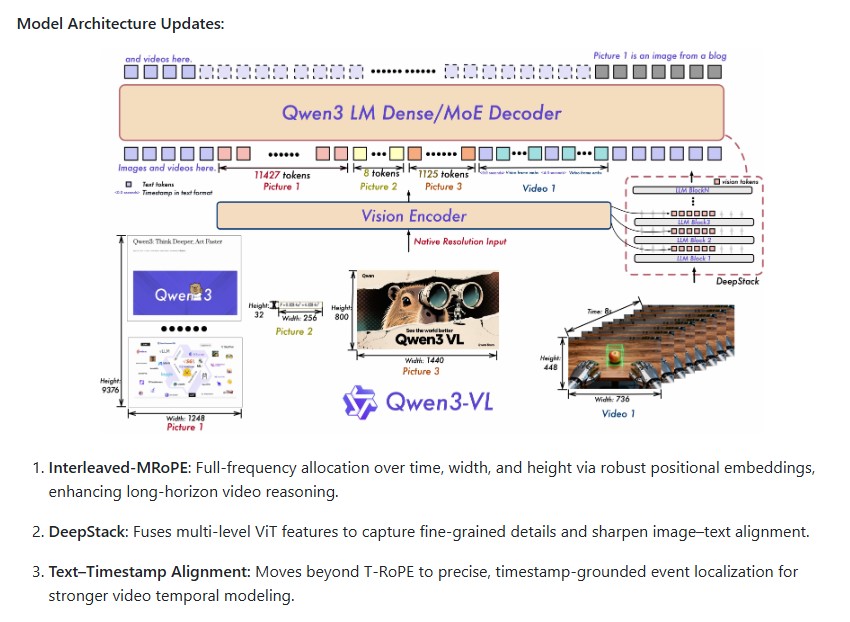
Architectural Innovations
The Qwen3-VL-8B-Instruct model introduces several key architectural upgrades:
- Interleaved-MRoPE (Multi-Dimensional Rotary Position Embeddings): Enables robust positional encoding across temporal and spatial dimensions, enhancing long-horizon video understanding.
- DeepStack Feature Fusion: Combines multi-level Vision Transformer (ViT) layers to capture fine-grained details and improve image-text alignment.
- Text–Timestamp Alignment: Provides temporal grounding for video comprehension allowing precise event tracking and sequencing.
These innovations together empower the model to perform fine-grained, temporally aware reasoning that bridges language, vision and time.
Quickstart Guide: Using Qwen3-VL-8B-Instruct
The model can be easily deployed using Hugging Face Transformers or ModelScope.
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
model = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-8B-Instruct", dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-8B-Instruct")
messages = [{
"role": "user",
"content": [
{"type": "image", "image": "https://example.com/demo.jpeg"},
{"type": "text", "text": "Describe this image in detail."},
],
}]
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
inputs = inputs.to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=128)
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(output_text)
This snippet demonstrates how simple it is to start interacting with Qwen3-VL using just a few lines of code. Developers can further optimize inference using flash_attention_2, enabling faster and more memory-efficient multi-image or video processing.
Real-World Applications of Qwen3-VL-8B-Instruct
Qwen3-VL’s capabilities extend far beyond academic research. Here are some powerful real-world applications:
- AI Agents & Automation: Visual agents that interact with desktop or mobile GUIs.
- Video Analysis & Surveillance: Long-context temporal reasoning for event detection.
- Document Intelligence: Multilingual OCR for complex layouts and handwritten text.
- STEM Education: Visual and textual reasoning for math and science learning tools.
- Creative Industries: Automatic code generation from design mockups or storyboarding.
- Healthcare: Medical image and report analysis with spatial and textual grounding.
Performance and Scalability
Qwen3-VL-8B-Instruct offers dense and Mixture of Experts (MoE) variants for deployment across a wide range of environments from edge devices to cloud-scale infrastructure. It’s optimized for BF16 tensors and compatible with Safetensors format for efficient model loading and inference.
With nearly 180,000 downloads per month and support for multiple inference providers (including Novita), Qwen3-VL is widely adopted for real-world, production-grade AI workloads.
Conclusion
Qwen3-VL-8B-Instruct is not just an incremental upgrade – it’s a milestone in multimodal AI. By combining deep linguistic understanding, advanced visual reasoning, and long-context processing into one unified architecture, Qwen sets a new benchmark for what AI systems can achieve.
From interpreting the physical world to generating meaningful, structured responses, Qwen3-VL redefines the boundaries of AI perception, reasoning and creativity. Whether you’re a developer, researcher or enterprise innovator, this model offers the intelligence, scalability and precision needed to shape the next era of vision-language computing.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- LangChain: The Ultimate Framework for Building Reliable AI Agents and LLM Applications
- Master Machine Learning: Explore the Ultimate “Machine-Learning-Tutorials” Repository
- LangGraph by LangChain-AI: The Framework Powering Stateful, Long-Running AI Agents
- OpenSearch for AI Agents: Empowering Intelligent Search and Automation
- AgentFly: The Future of Reinforcement Learning for Intelligent Language Model Agents
2 thoughts on “Qwen3-VL-8B-Instruct — The Next Generation of Vision-Language Intelligence by Qwen”