
In the ever-evolving landscape of artificial intelligence and natural language processing (NLP), BERT (Bidirectional Encoder Representations from Transformers) stands as a monumental breakthrough. Developed by researchers at Google AI in 2018, BERT introduced a new way of understanding the context of language by using deep bidirectional training of the Transformer architecture. Unlike previous models that read text sequentially (either left-to-right or right-to-left), BERT reads the entire text at once, allowing it to capture context from both directions simultaneously.
This approach reshaped how machines comprehend human language, enabling models to perform exceptionally well on a wide range of NLP tasks such as question answering, sentiment analysis and text classification. BERT not only raised the performance bar but also democratized language understanding by being open-sourced allowing researchers and businesses worldwide to build upon its foundation.
The Need for Better Language Understanding
Before BERT, most NLP models relied on unidirectional approaches like ELMo, GPT and traditional RNN-based architectures. These models processed text in one direction, limiting their ability to fully understand contextual relationships. For instance, in the sentence “The bank near the river is quiet,” older models struggled to distinguish whether “bank” referred to a financial institution or the side of a river without looking ahead in the sentence.
Language is inherently contextual and dependent on surrounding words. BERT solved this problem by using a bidirectional training approach, allowing the model to look at both left and right context at the same time. This capability made BERT’s language understanding far more natural and nuanced aligning closely with how humans interpret meaning.
Understanding the BERT Architecture
At its core, BERT is built upon the Transformer architecture originally introduced in the paper “Attention Is All You Need” (Vaswani et al., 2017). The Transformer relies entirely on self-attention mechanisms rather than recurrent or convolutional layers. This allows BERT to model relationships between words in a sentence regardless of their distance from each other.
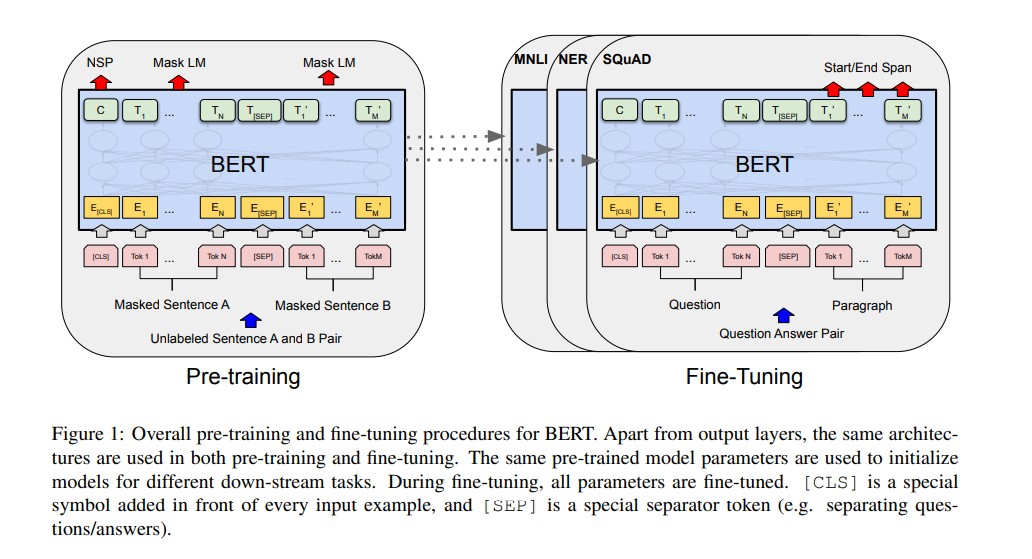
BERT consists only of the encoder part of the Transformer, which is responsible for creating powerful contextual embeddings for each word. It was released in two main configurations:
- BERT Base: 12 layers (Transformer blocks), 768 hidden units and 12 attention heads (110 million parameters).
- BERT Large: 24 layers, 1024 hidden units and 16 attention heads (340 million parameters).
These deep architectures enable BERT to capture intricate linguistic patterns across large datasets making it one of the most expressive models in NLP history.
Pre-training Objectives: MLM and NSP
One of BERT’s greatest innovations lies in its pre-training objectives which help the model learn language representations before being fine-tuned for specific tasks.
1. Masked Language Modeling (MLM)
During pre-training, BERT randomly masks 15% of words in a sentence and tries to predict them based on surrounding context. For example, given the sentence “The cat [MASK] on the mat,” BERT learns to fill in the blank with “sat.” This teaches the model to understand relationships between words bidirectionally.
2. Next Sentence Prediction (NSP)
Another key task involves predicting whether one sentence logically follows another. For example:
- Sentence A: “The weather is great today.”
- Sentence B: “Let’s go for a picnic.”
BERT learns to identify that B follows A logically. This ability helps it perform better in tasks that involve relationships between sentences such as question answering or natural language inference.
Together, MLM and NSP allow BERT to develop a deep and flexible understanding of language structure, semantics and context.
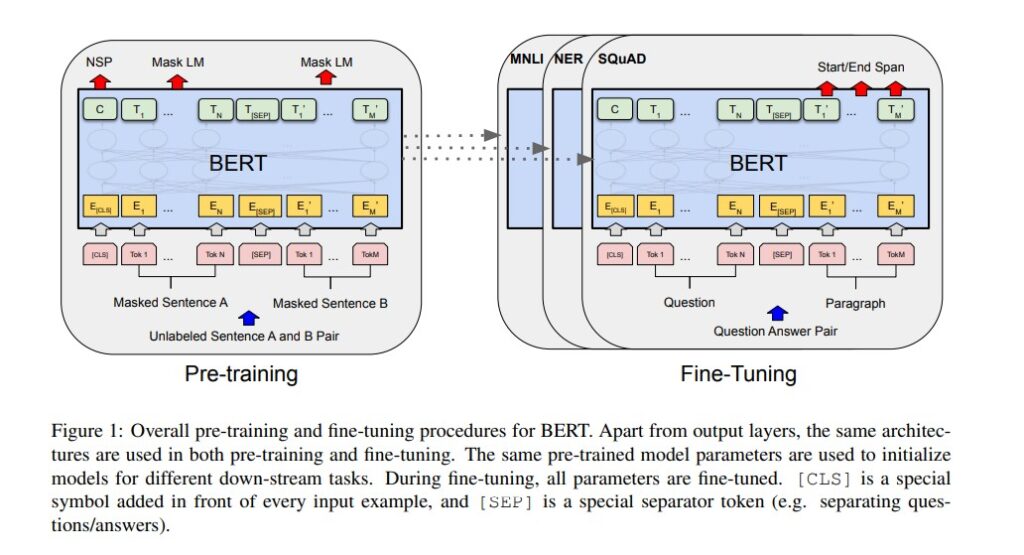
Fine-Tuning for Downstream NLP Tasks
Once pre-trained on massive text corpora like Wikipedia and BookCorpus, BERT can be fine-tuned with just one additional output layer to perform a variety of NLP tasks. Fine-tuning requires relatively little task-specific data, making BERT accessible for numerous applications.
Some of the tasks where BERT achieved groundbreaking results include:
- Question Answering (e.g., SQuAD dataset): BERT set new records in extracting correct answers from passages.
- Sentiment Analysis: It accurately determines positive, negative or neutral tones in text.
- Named Entity Recognition (NER): Identifying proper nouns like names, locations or organizations.
- Text Classification: Categorizing documents or messages by topic or intent.
- Paraphrase Detection: Understanding whether two sentences mean the same thing.
This fine-tuning versatility made BERT a general-purpose language model paving the way for task-specific adaptations like RoBERTa, ALBERT and DistilBERT.
Impact and Advancements Inspired by BERT
BERT’s release triggered a revolution in NLP research and applications. It became the foundation for transformer-based models that followed, such as:
- RoBERTa (Facebook): Improved performance by removing the NSP task and training on larger data.
- ALBERT (Google): Reduced model size through parameter sharing while retaining accuracy.
- DistilBERT (Hugging Face): A smaller, faster version of BERT suitable for real-time use.
- GPT (OpenAI): Focused on generative tasks using unidirectional training inspired by BERT’s architecture.
These advancements solidified the Transformer family’s dominance across language, vision and even multimodal domains.
In the business world, BERT has transformed search engines, chatbots and virtual assistants by improving contextual understanding. Google integrated BERT into its search algorithm in 2019, helping users get more relevant and natural search results.
Challenges and Limitations
While BERT’s capabilities are remarkable, it is not without limitations. The model’s computational cost is high requiring significant resources for training and fine-tuning. Additionally since it is trained on large internet corpora, biases in training data can reflect in its predictions. Researchers continue to explore ways to make BERT more efficient, ethical and interpretable.
Conclusion
BERT fundamentally redefined what machines could understand about human language. Its ability to learn from both directions of text, combined with large-scale pre-training has made it a cornerstone of modern NLP. Today, nearly every state-of-the-art language model builds upon BERT’s foundation demonstrating the enduring power of bidirectional transformers.
As we move toward more advanced models and multimodal AI systems, BERT’s legacy continues to inspire innovations in how we teach machines to understand and generate language with human-like precision.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- The Transformer Architecture: How Attention Revolutionized Deep Learning
- Concerto: How Joint 2D-3D Self-Supervised Learning Is Redefining Spatial Intelligence
- Pico-Banana-400K: The Breakthrough Dataset Advancing Text-Guided Image Editing
- PokeeResearch: Advancing Deep Research with AI and Web-Integrated Intelligence
- DeepAgent: A New Era of General AI Reasoning and Scalable Tool-Use Intelligence
3 thoughts on “BERT: Revolutionizing Natural Language Processing with Bidirectional Transformers”