
In the evolving landscape of artificial intelligence, large language models (LLMs) like GPT, Claude and Qwen have demonstrated remarkable abilities from generating human-like text to solving complex problems in mathematics, coding, and logic. Yet, despite their success, these models often struggle with multi-step reasoning, especially when each step depends critically on the previous one. Traditional training approaches such as Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) show limitations in effectively teaching LLMs how to reason through such problems.
To address this challenge, researchers from Google Cloud AI and UCLA introduced a groundbreaking framework called Supervised Reinforcement Learning (SRL). This innovative approach combines the strengths of supervision and reinforcement learning to teach models how to think and act step by step mimicking how human experts reason through complex tasks.
SRL is designed to help smaller and open-source models perform sophisticated reasoning tasks that were previously unachievable using conventional methods. It transforms the model training paradigm by integrating expert guidance, structured feedback and adaptive decision-making into one cohesive process.
The Limitations of Traditional Approaches
1. Supervised Fine-Tuning (SFT)
Supervised Fine-Tuning, a widely used method for training LLMs, involves exposing the model to expert-generated demonstrations and asking it to imitate them token by token. While effective for simple tasks, this rigid imitation causes overfitting – the model memorizes surface-level patterns without truly understanding the reasoning process behind them.
When faced with novel problems, such models fail to generalize because they lack the ability to plan or reason beyond what they have directly seen during training. The result is shallow reasoning and limited flexibility.
2. Reinforcement Learning with Verifiable Rewards (RLVR)
Reinforcement Learning, on the other hand, rewards models for producing correct answers. This works well when models can occasionally reach correct outcomes during training. However, for difficult problems where correct answers are rarely found, reward signals become too sparse offering the model little guidance on how to improve.
Penalizing every incorrect response can even lead to instability, making learning inefficient and unreliable. As a result, both SFT and RLVR fail to adequately train models to reason effectively through multi-step challenges.’
Introducing Supervised Reinforcement Learning (SRL)
Supervised Reinforcement Learning (SRL) bridges the gap between imitation and reinforcement learning by introducing a hybrid strategy. Instead of forcing the model to imitate entire expert trajectories or rewarding only final answers, SRL teaches models to think and act in steps just like a human solving a problem.
Here’s how it works:
- Step Decomposition: Expert demonstrations are broken down into logical “actions,” each representing a single decision or operation within a reasoning chain.
- Internal Reasoning: The model generates its own inner monologue – a self-reflective reasoning process before committing to an action.
- Step-Wise Rewarding: After each step, the model receives a dense reward based on how closely its action matches the expert’s corresponding step.
This design provides richer learning signals even when the overall solution is incorrect, helping the model learn from partially correct reasoning paths. It encourages structured thinking while allowing creative flexibility in problem-solving.
Why SRL Works ?
The success of SRL lies in its granular feedback system. Unlike RLVR, which rewards only complete success, SRL evaluates progress at every stage. By comparing the model’s intermediate steps with expert actions, SRL provides a continuous stream of feedback transforming problem-solving into a guided learning journey.
Moreover, this structure promotes step-wise planning, verification and adaptation, helping models develop the ability to reflect on their reasoning. Over time, the model learns not only what the right answer is but how to arrive there efficiently.
Experimental Results: Bridging the Performance Gap
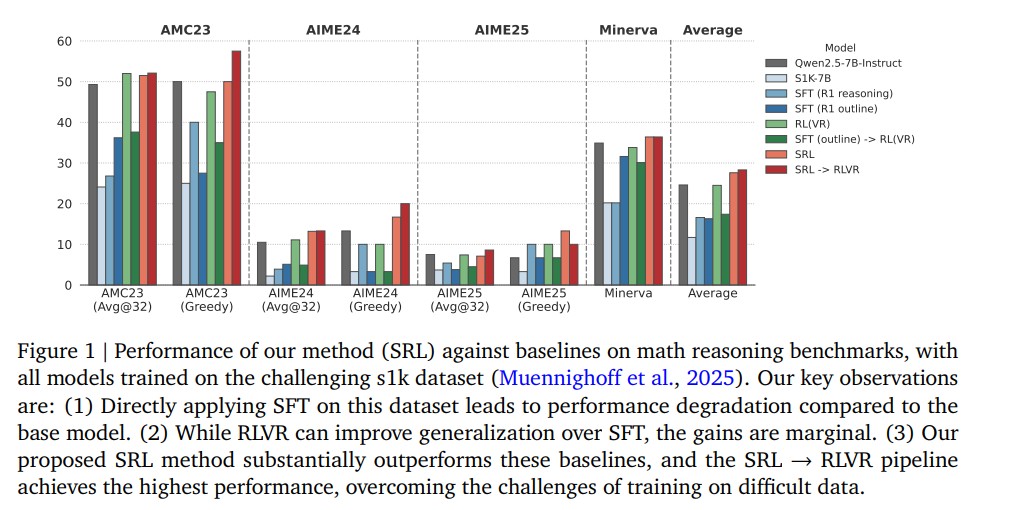
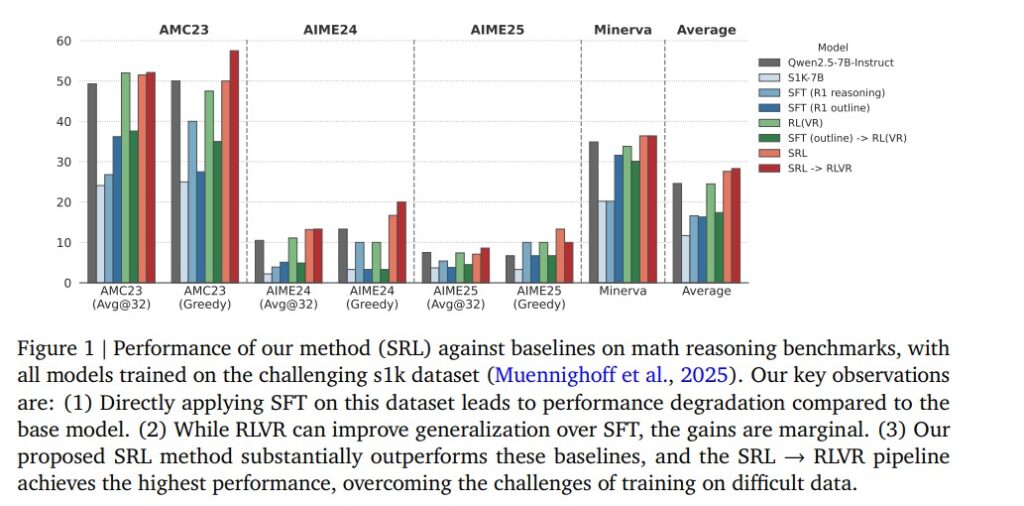
In extensive experiments on challenging mathematical reasoning benchmarks such as AMC23, AIME24, AIME25 and Minerva Math, the SRL approach achieved significant performance improvements over traditional SFT and RLVR methods.
Key observations include:
- Applying SFT alone on difficult datasets led to degraded performance due to overfitting.
- RLVR offered minor improvements but remained limited by sparse rewards.
- SRL, however delivered consistent and strong results across benchmarks with up to 3.7% higher accuracy than RLVR when used as a precursor to reinforcement fine-tuning.
Furthermore, SRL-trained models exhibited more natural reasoning behaviors such as interleaving planning, step verification and self-reflection throughout the problem-solving process. These emergent patterns resembled human-like thought processes suggesting a major step forward in AI reasoning maturity.
Beyond Mathematics: Application in Software Engineering
SRL’s impact extends beyond mathematics into software engineering, where reasoning and decision-making are critical. In experiments involving SWE-Bench, a benchmark for real-world coding problems, SRL was applied to the Qwen2.5-Coder-7B model.
Compared with the baseline and supervised fine-tuning models, SRL achieved a 74% improvement in the code-patch resolve rate and doubled the performance in end-to-end evaluations. This demonstrates that SRL not only enhances logical reasoning but also empowers AI systems to handle complex, real-world tasks such as debugging and autonomous code repair.
The Road Ahead
Supervised Reinforcement Learning represents a paradigm shift in how we train reasoning-oriented LLMs. By merging dense supervision with the exploration-driven philosophy of reinforcement learning, SRL enables:
- Better generalization across unseen tasks
- Faster learning through consistent feedback
- Improved adaptability in dynamic environments
Looking forward, the researchers envision SRL as a foundational step toward building truly agentic AI systems – models capable of self-guided reasoning, long-term planning and collaborative problem-solving. Combining SRL with advanced RL methods like RLVR creates a powerful training pipeline that continues to refine and enhance AI intelligence.
Conclusion
Supervised Reinforcement Learning (SRL) marks a pivotal advancement in AI training methodology. By teaching models to reason step by step and rewarding them for process-oriented accuracy, SRL overcomes the limitations of both imitation learning and traditional reinforcement learning.
Through extensive validation in mathematical reasoning and software engineering, SRL has proven to be a robust, scalable and versatile framework. It empowers even smaller language models to tackle reasoning tasks once thought beyond their capabilities.
As AI continues to evolve, SRL provides a clear path forward – one that emphasizes understanding, adaptability and collaboration over mere prediction. It lays the foundation for the next generation of intelligent, reasoning-capable AI systems.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Context Engineering 2.0: Redefining Human–Machine Understanding
- OpenAI Evals: The Framework Transforming LLM Evaluation and Benchmarking
- Skyvern: The Future of Browser Automation Powered by AI and Computer Vision
- Steel Browser: The Open-Source Browser API Powering AI Agents and Automation
- Bytebot: The Future of AI Desktop Automation
4 thoughts on “Supervised Reinforcement Learning: A New Era of Step-Wise Reasoning in AI”