
Speech recognition has evolved rapidly over the past decade, transforming the way we interact with technology. From voice assistants to transcription services and real-time translation tools, the ability of machines to understand human speech has redefined accessibility, communication and automation. However, one of the major challenges that persisted for years was achieving robust, multilingual and accurate speech recognition across diverse environments.
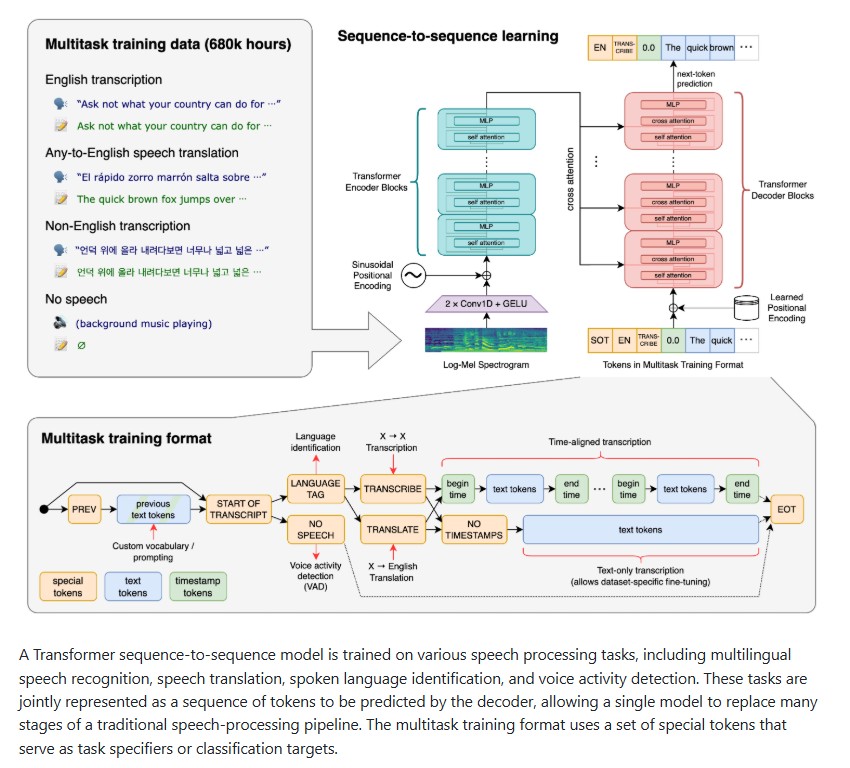
OpenAI’s Whisper addresses this challenge head-on. Released as a general-purpose speech recognition model, Whisper leverages large-scale weak supervision to deliver state-of-the-art accuracy in transcription, translation and language identification. Its open-source availability makes it one of the most impactful contributions to the field of Automatic Speech Recognition (ASR) in recent years.
In this blog, we explore the capabilities, architecture, and real-world impact of Whisper and why it represents the future of speech recognition technology.
What Is Whisper?
It is an open-source multitask speech recognition model developed by OpenAI. Unlike traditional ASR systems that require separate pipelines for transcription, translation and language detection, Whisper unifies these tasks within a single Transformer-based sequence-to-sequence architecture.
The model has been trained on a massive dataset containing diverse audio samples in multiple languages. This large-scale training enables Whisper to handle noisy environments, various accents and complex linguistic contexts with impressive accuracy.
Key Features
- Multilingual Speech Recognition: Supports dozens of languages with robust transcription quality.
- Speech Translation: Can directly translate non-English speech into English text.
- Language Identification: Automatically detects the language being spoken.
- Voice Activity Detection: Differentiates between speech and silence, improving transcription precision.
- Open Source: Freely available under the MIT License for developers, researchers and organizations.
The Architecture Behind Whisper
At the heart of Whisper is a Transformer sequence-to-sequence model — the same architecture that powers some of the world’s most powerful AI models. The system jointly trains on multiple speech tasks, combining recognition, translation and identification into a unified framework.
1. Multitask Token Representation
It uses a set of special tokens to represent different tasks. For example, when performing translation or transcription, specific tokens are used to condition the model on the desired task. This allows Whisper to handle multiple functions seamlessly without switching between specialized systems.
2. Large-Scale Weak Supervision
The model is trained using a vast collection of publicly available audio data, much of which includes imperfect or automatically generated transcriptions — a method known as weak supervision. Despite the imperfections, the large data scale helps Whisper generalize remarkably well to new domains and speakers.
3. Transformer-Based Sequence Modeling
Whisper’s architecture follows the classic encoder-decoder setup:
- The encoder processes the input audio and converts it into a sequence of hidden states.
- The decoder then predicts tokens (words or characters) based on these states, generating readable transcriptions or translations.
This design allows Whisper to maintain accuracy even when handling complex linguistic nuances and background noise.
Model Variants and Performance
It comes in six model sizes offering flexibility between performance, accuracy and hardware requirements.
| Model Size | Parameters | English-only | Multilingual | VRAM Required | Relative Speed |
| tiny | 39M | tiny.en | tiny | ~1 GB | ~10x |
| base | 74M | base.en | base | ~1 GB | ~7x |
| small | 244M | small.en | small | ~2 GB | ~4x |
| medium | 769M | medium.en | medium | ~5 GB | ~2x |
| large | 1.55B | — | large | ~10 GB | 1x |
| turbo | 809M | — | turbo | ~6 GB | ~8x |
The English-only (.en) versions perform slightly better for English transcription, especially in smaller models while the multilingual versions are designed for global language coverage. The turbo model is a high-performance variant of large-v3 optimized for faster inference with minimal accuracy trade-offs.
Installation and Setup
Setting up Whisper is straightforward and can be done via Python’s package manager:
pip install -U openai-whisper
Alternatively, to install the latest version directly from GitHub:
pip install git+https://github.com/openai/whisper.git
You’ll also need ffmpeg, a popular multimedia framework to handle audio decoding:
# Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# macOS (Homebrew)
brew install ffmpeg
# Windows (Chocolatey)
choco install ffmpeg
If you encounter installation errors related to tiktoken or setuptools_rust, simply install Rust and the necessary dependencies.
Using Whisper: Command Line and Python API
It provides two primary ways to perform transcription via the command line or through Python.
Command Line Example
To transcribe audio using the turbo model:
whisper audio.mp3 --model turbo
To translate non-English speech into English:
whisper japanese.wav --model medium --language Japanese --task translate
Python Example
For developers, Whisper’s Python API is simple and powerful:
import whisper
model = whisper.load_model("turbo")
result = model.transcribe("speech.mp3")
print(result["text"])
You can also detect the language automatically:
audio = whisper.load_audio("audio.mp3")
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
This ease of use makes it ideal for both research and production environments.
Multilingual Capabilities
It is trained to handle a wide variety of languages and accents. It can transcribe audio from diverse linguistic backgrounds and even perform cross-lingual translation. For instance, a Spanish audio clip can be directly translated into English without using a separate translation model.
This makes it particularly valuable for global applications such as:
- Multilingual transcription services
- Cross-border communication tools
- Accessibility features for global audiences
- Media localization and subtitling
Performance and Accuracy
Whisper’s performance has been extensively benchmarked across various datasets like Common Voice and Fleurs. The large-v3 model achieves state-of-the-art accuracy, outperforming many closed-source systems in terms of Word Error Rate (WER) and Character Error Rate (CER).
The turbo model, introduced later, provides a near-identical performance to the large-v3 model but with up to 8x faster inference speed making it suitable for real-time transcription tasks.
Real-World Applications
Whisper’s flexibility and open-source availability make it a cornerstone for a wide range of industries:
- Accessibility: Empowering the hearing-impaired community with live captioning tools.
- Education: Enabling multilingual transcription for lectures and online learning.
- Media Production: Automating subtitle and translation workflows for videos.
- Customer Support: Transcribing and analyzing multilingual customer interactions.
- Research: Offering a foundation for speech-to-text experimentation and language modeling.
Its reliability across multiple languages and accents makes it an invaluable tool for developers, educators, journalists and businesses alike.
Open Source and Community Impact
Released under the MIT License, Whisper is entirely open-source. This fosters collaboration, innovation, and adaptation across academia and industry. Thousands of developers have integrated Whisper into their own applications, from transcription tools to AI-powered assistants.
The project has already amassed over 90,000 GitHub stars, highlighting its global adoption and community trust.
Conclusion
It’s Whisper represents a major leap forward in speech recognition technology. With its Transformer-based architecture, multilingual capabilities, and open-source accessibility, it brings accurate, inclusive, and efficient speech understanding to everyone from researchers and developers to content creators and accessibility advocates.
Whisper not only simplifies complex audio tasks but also democratizes speech AI, allowing individuals worldwide to build applications that transcend linguistic boundaries. As the demand for human-computer interaction grows, it stands as a reliable, transparent, and powerful foundation for the next generation of voice-driven technologies.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Omnilingual ASR: Meta’s Breakthrough in Multilingual Speech Recognition for 1600+ Languages
- LEANN: The Bright Future of Lightweight, Private, and Scalable Vector Databases
- Reducing Hallucinations in Vision-Language Models: A Step Forward with VisAlign
- DeepEyesV2: The Next Leap Toward Agentic Multimodal Intelligence
- Agent-o-rama: The End-to-End Platform Transforming LLM Agent Development
3 thoughts on “Whisper by OpenAI: The Revolution in Multilingual Speech Recognition”