
In a world where digital content exists in hundreds of languages, finding the right information efficiently has become more important than ever. Whether it’s an e-commerce business catering to international customers or a global enterprise managing data across countries, language often becomes a barrier. This is where Artificial Intelligence (AI) steps in to revolutionize multilingual search.
One of the most innovative AI models leading this change is LFM2-ColBERT-350M by LiquidAI, available on Hugging Face. This model is designed to enable multilingual document retrieval with high accuracy and speed, bridging language gaps like never before. It combines advanced transformer architectures with efficient late interaction mechanisms, ensuring precise and scalable results across languages such as English, French, Arabic, Japanese, Korean and more.
In this blog, we will explore how multilingual retrieval models like LFM2-ColBERT-350M work, why they are essential in today’s data-driven world and how they are transforming industries ranging from e-commerce to enterprise intelligence.
Understanding LFM2-ColBERT-350M
LFM2-ColBERT-350M is a multilingual AI retriever model that uses a technique called late interaction to balance accuracy and efficiency. Traditionally, search systems used simple keyword matching which often failed to capture the meaning behind a query. LFM2-ColBERT-350M, however goes beyond keywords – it understands the semantic meaning of text across different languages.
This means you can store a product description in English and the model can accurately retrieve it even when the query is in German, French or Arabic. It performs both document retrieval and ranking ensuring users get the most relevant information quickly.
With 353 million parameters, a context length of 32,768 tokens and support for eight major languages, the model is built for large-scale, high-accuracy retrieval tasks. Despite its size, it runs with remarkable speed on par with smaller models – thanks to the efficient LFM2 backbone.
How Multilingual Retrieval Works ?
To understand the importance of LFM2-ColBERT-350M, it helps to grasp how multilingual retrieval functions. At its core, it’s about teaching AI to connect similar meanings expressed in different languages.
For example, if a user searches “meilleur smartphone” (French for “best smartphone”), the model can retrieve English-language reviews and specifications. It achieves this through a shared embedding space where text in different languages is represented as numerical vectors that reflect their meanings.
LFM2-ColBERT-350M uses MaxSim similarity functions to measure how closely these vectors align, enabling precise cross-lingual matches. Its late interaction approach allows it to process document and query embeddings separately, maintaining scalability without sacrificing performance.
Applications Across Industries
1. E-Commerce Search and Product Discovery
For global retailers, providing search results that match user intent regardless of language is crucial. LFM2-ColBERT-350M enables semantic search at scale, allowing users to find relevant products in their native language even when listings are in another. This improves user experience, increases conversions and enhances accessibility in international markets.
2. Enterprise Knowledge Assistants
Corporations generate massive volumes of internal data – legal documents, technical reports and financial summaries often written in different languages. This model can act as an enterprise knowledge retriever, helping employees find information faster across global branches without translation delays.
3. On-Device Semantic Search
LFM2-ColBERT-350M can be used for edge and on-device search applications, allowing users to find emails, notes, or files by asking natural-language questions. For example, a user might ask, “Show me last week’s financial report,” and the system can retrieve the document instantly even if the content isn’t in the same language as the query.
4. Research and Multilingual Data Analysis
Academic and research institutions dealing with multilingual datasets can use this model to perform cross-language retrieval and reranking enhancing global collaboration and reducing the need for language-specific models.
Performance and Benchmarks
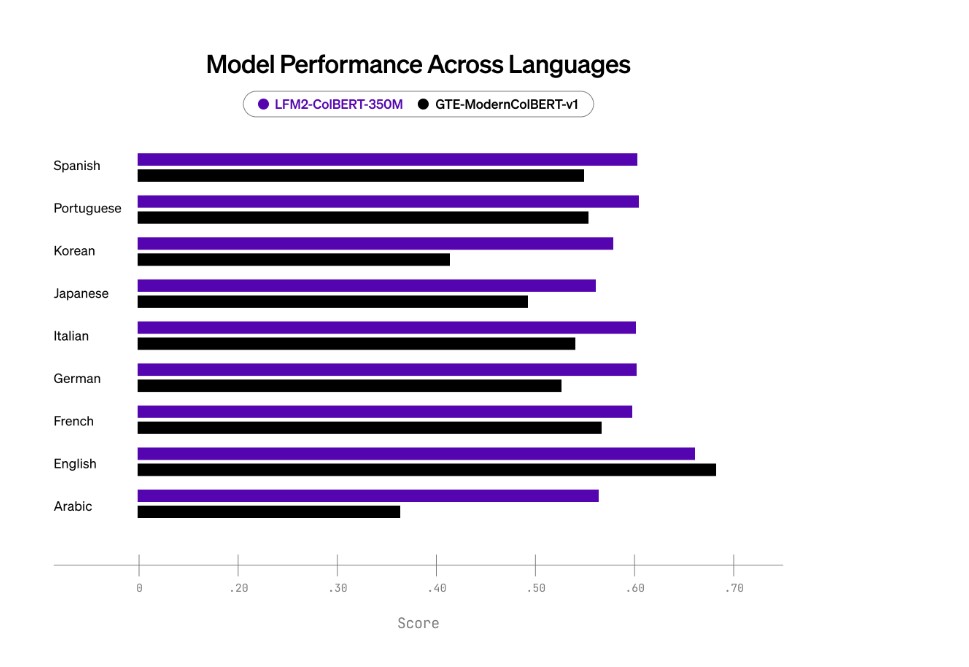
On the NanoBEIR multilingual benchmark, LFM2-ColBERT-350M achieved top-tier performance across languages like German, Arabic, Korean, and Japanese. It demonstrated state-of-the-art (SOTA) cross-lingual retrieval results outperforming previous models such as GTE-ModernColBERT-v1.
Its average retrieval accuracy (NDCG@10) exceeded 50% for English and major European languages, showing strong generalization across linguistic variations. This makes it ideal for multilingual environments where both documents and queries may differ in language.
Additionally despite having twice the parameter size of smaller models, LFM2-ColBERT-350M maintains competitive inference speed, handling queries and documents with minimal latency. This is achieved through FastPLAID indexing and optimized PyLate integration, ensuring efficient similarity search even at scale.
Ease of Integration and Usage
One of the key strengths of this model is its accessibility for developers. Using the PyLate library, developers can quickly integrate LFM2-ColBERT-350M into their Retrieval-Augmented Generation (RAG) pipelines.
The process involves:
- Indexing documents using the PLAID index.
- Encoding documents and queries with the model.
- Retrieving or reranking relevant documents using semantic similarity scores.
Once the index is built, it can be reused multiple times without re-encoding, making it efficient for large datasets or enterprise-scale applications.
Why LFM2-ColBERT-350M Matters
In a rapidly globalizing world, communication barriers remain one of the biggest challenges in accessing information. LFM2-ColBERT-350M represents a step forward in AI-powered multilingual understanding, enabling systems that connect people across languages effortlessly.
From improving user experiences to making research more inclusive, this model demonstrates how advanced retrieval systems can bring us closer to truly universal access to information. As AI continues to evolve, models like LFM2-ColBERT-350M show that the future of search is not just smarter – it’s more human, inclusive and connected.
Conclusion
The LFM2-ColBERT-350M model stands as a powerful innovation in multilingual AI retrieval. Its combination of accuracy, efficiency, and scalability makes it an essential tool for modern applications across industries. By bridging language barriers, it not only enhances global communication but also sets new standards for AI-driven search and discovery.
Whether it’s helping users shop across languages, supporting multilingual workplaces or accelerating global research, LFM2-ColBERT-350M is redefining how we interact with information. The model reminds us that the future of Artificial Intelligence lies not just in processing data but in understanding it, across every language.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- S3PRL Toolkit: Advancing Self-Supervised Speech Representation Learning
- How to Run and Fine-Tune Kimi K2 Thinking Locally with Unsloth
- IndicWav2Vec: Building the Future of Speech Recognition for Indian Languages
- Distil-Whisper: Faster, Smaller, and Smarter Speech Recognition by Hugging Face
- Whisper by OpenAI: The Revolution in Multilingual Speech Recognition
2 thoughts on “Breaking Language Barriers with AI: The Power of LFM2-ColBERT-350M in Multilingual Search”