
In the rapidly evolving world of AI audio generation, neural vocoders play a critical role in transforming model outputs into realistic, high-quality sound. One of the most advanced and widely adopted solutions today is BigVGAN v2 44kHz 128-band 512x from NVIDIA. Designed as a universal neural vocoder and trained on large-scale diverse datasets, BigVGAN v2 delivers studio-quality waveform synthesis from mel spectrogram inputs.
With support for 44 kHz sampling rate and a 512x upsampling ratio, this model is built for high-fidelity speech, music, and environmental sound generation. In this comprehensive guide, we explore its architecture, features, performance improvements, installation process, and real-world applications.
What Is BigVGAN?
BigVGAN (Big Vocoder GAN) is a universal neural vocoder introduced in the research paper BigVGAN: A Universal Neural Vocoder with Large-Scale Training (arXiv: 2206.04658). It is designed to convert mel spectrograms into raw audio waveforms using Generative Adversarial Networks (GANs).
Unlike traditional vocoders that are often limited to speech-specific tasks, BigVGAN is trained on large-scale and diverse audio datasets, enabling it to generalize across:
- Multi-language speech
- Environmental sounds
- Musical instruments
- Mixed audio domains
The v2 44kHz 128-band 512x checkpoint represents one of the most powerful configurations available on Hugging Face, optimized for high-resolution audio synthesis.
Key Specifications of BigVGAN v2 44kHz 128-band 512x
Here are the core technical details:
- Sampling Rate: 44 kHz
- Mel Bands: 128
- Maximum Frequency (fmax): 22050 Hz
- Upsampling Ratio: 512x
- Parameters: 122 million
- Training Steps: 5 million
- Dataset: Large-scale compilation of diverse audio
- License: MIT
This configuration is specifically built for professional-grade audio output, making it ideal for music production, high-fidelity speech synthesis, and cinematic sound design.
What’s New in BigVGAN v2?
BigVGAN v2 introduces several major improvements over the original version:
1. Custom CUDA Kernel for Faster Inference
One of the standout enhancements is the fully fused CUDA kernel for anti-aliased activation (upsampling + activation + downsampling). This optimization delivers:
- 1.5x to 3x faster inference on a single A100 GPU
- Reduced latency in production systems
- Improved efficiency for real-time applications
The kernel is built automatically using nvcc and ninja during first use and is compatible with CUDA 12.1.
2. Improved Discriminator and Loss Functions
BigVGAN v2 uses:
- Multi-scale sub-band CQT discriminator
- Multi-scale mel spectrogram loss
These improvements significantly enhance perceptual audio quality and reduce artifacts.
3. Larger and More Diverse Training Data
The model was trained on a massive and diverse audio dataset, including:
- Multi-language speech
- Environmental recordings
- Instrumental audio
This large-scale training enables strong generalization across domains.
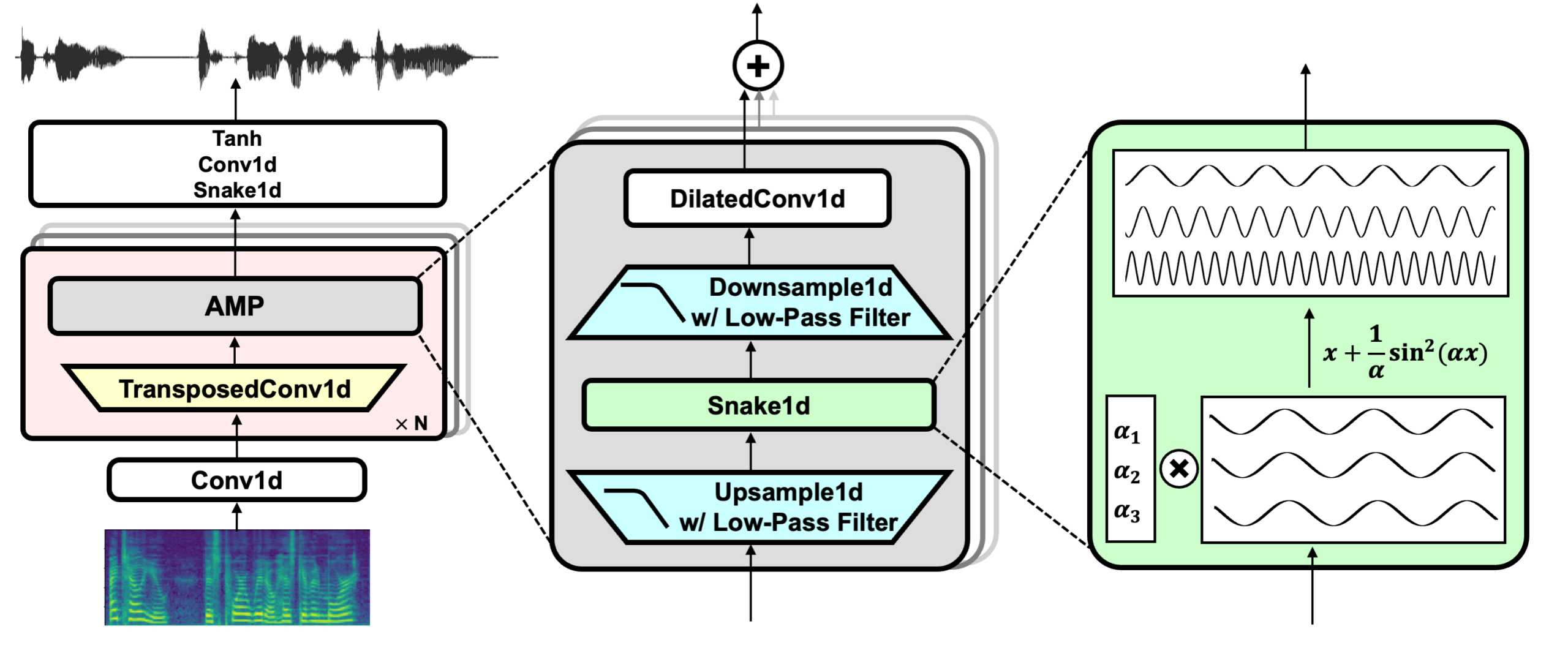
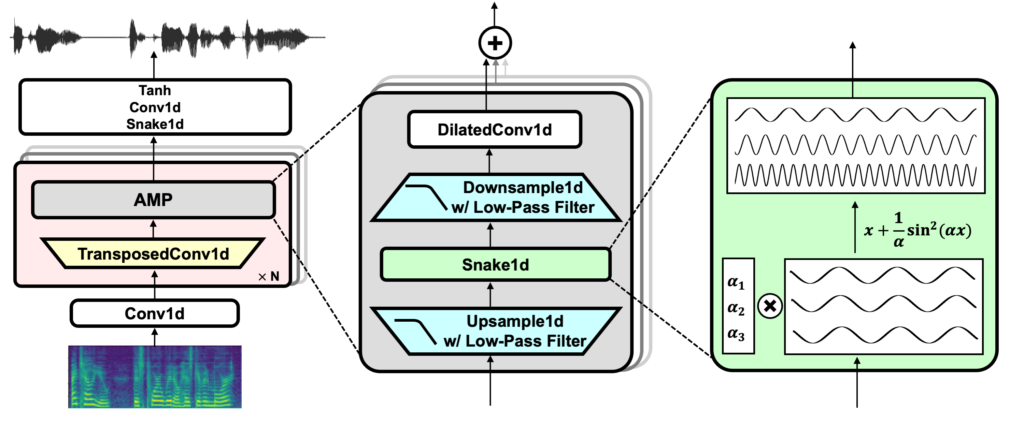
How BigVGAN Works
At its core, BigVGAN operates in three stages:
- Input waveform is converted into a mel spectrogram.
- The mel spectrogram is passed into the generator network.
- The generator synthesizes a high-resolution waveform.
Developers can load the pretrained checkpoint directly from Hugging Face using PyTorch. The workflow typically involves:
- Loading the model
- Removing weight normalization
- Computing mel spectrogram
- Running inference to generate waveform
The output waveform can then be converted into 16-bit linear PCM for playback or storage.
Installation and Setup
To install the model:
git lfs install git clone https://huggingface.co/nvidia/bigvgan_v2_44khz_128band_512x
For faster inference, you can enable the custom CUDA kernel:
model = bigvgan.BigVGAN.from_pretrained(
"nvidia/bigvgan_v2_44khz_128band_512x",
use_cuda_kernel=True
)
Ensure:
- CUDA 12.1 is installed
- nvcc matches your PyTorch CUDA version
- ninja build system is available
Performance and Quality Advantages
BigVGAN v2 44kHz 128-band 512x offers several competitive advantages:
High-Fidelity Output
With 44 kHz sampling and 128 mel bands, the model captures fine acoustic details essential for:
- Music production
- Audiobook narration
- Film sound design
- Voice cloning systems
Strong Generalization
Thanks to large-scale training, BigVGAN performs well across domains without needing task-specific retraining.
Production-Ready Deployment
- Pretrained weights available on Hugging Face
- MIT license for flexible usage
- PyTorch-based implementation
- Optimized GPU inference
Comparison with Other Vocoders
Compared to traditional neural vocoders like HiFi-GAN or WaveGlow:
- BigVGAN supports broader audio domains
- Offers higher sampling configurations
- Provides fused CUDA optimization
- Delivers improved perceptual quality through advanced discriminator design
Its scalability and training diversity make it particularly suitable for foundation audio models and large multimodal systems.
Real-World Applications
BigVGAN v2 44kHz 128-band 512x is widely used in:
Text-to-Speech (TTS) Systems
Converting model-generated mel spectrograms into natural-sounding speech.
Music Generation
Synthesizing realistic instrument sounds from generative music models.
Voice Conversion
Powering advanced voice cloning and character voice systems.
Multimodal AI
Supporting video, speech, and audio foundation models.
With over hundreds of thousands of downloads monthly, it has become one of the most trusted open-source neural vocoders available.
Why BigVGAN v2 44kHz 128-band 512x Matters
As AI-generated audio becomes mainstream, quality and efficiency are critical. BigVGAN v2 stands out because it combines:
- Large-scale training
- High-fidelity audio synthesis
- Production-grade performance optimization
- Open-source accessibility
For developers building next-generation AI audio systems, this model represents a powerful and flexible solution.
Conclusion
BigVGAN v2 44kHz 128-band 512x from NVIDIA sets a new benchmark in neural vocoder technology. With its high sampling rate, advanced GAN architecture, optimized CUDA inference, and large-scale training, it delivers exceptional audio realism across speech, music, and environmental sound tasks.
Whether you are developing a text-to-speech engine, music synthesis platform, or voice conversion system, BigVGAN v2 offers the performance, scalability, and quality needed for modern AI audio applications.
Its availability on Hugging Face, permissive MIT license, and GPU-accelerated inference make it one of the most production-ready open-source vocoders available today.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- TinyClaw by TinyAGI: A Multi-Agent, Multi-Team AI Assistant for 24/7 Automation
- Memori: The Future of SQL-Native Memory Engines for AI and LLM Applications
- The Rise of Distributed AI Systems: Why Scalable Multi-Agent Frameworks Are the Future of Artificial Intelligence
- Building a Real-Life GLaDOS: Inside the Open-Source Project Bringing Valve’s Iconic AI to Life
- MioCodec-25Hz-24kHz: A High-Efficiency Neural Audio Codec for Modern Spoken Language Modeling