
The rapid advancement of speech AI and spoken language models has created an urgent need for efficient neural audio codecs. As models grow larger and multilingual datasets expand into tens of thousands of hours, storage efficiency, token compactness, and reconstruction quality become critical bottlenecks. Traditional codecs often focus on perceptual audio quality alone, without considering downstream language modeling efficiency.
MioCodec-25Hz-24kHz emerges as a purpose-built solution for this new generation of speech systems. Developed by Chihiro Arata, MioCodec is a lightweight neural audio codec optimized specifically for spoken language modeling. It achieves ultra-low bitrate compression at 341 bps while maintaining high perceptual fidelity and enabling direct waveform synthesis without requiring an external vocoder.
This article provides a comprehensive, deep dive into MioCodec-25Hz-24kHz, covering its architecture, tokenization strategy, training methodology, multilingual dataset scale, use cases, and advantages for SpeechLM development.
What is MioCodec-25Hz-24kHz?
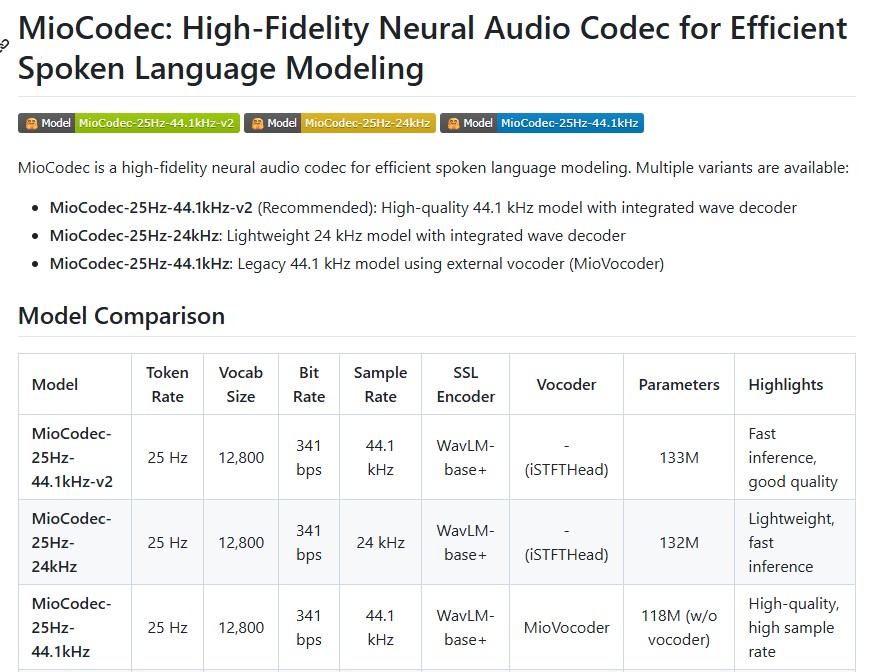
MioCodec-25Hz-24kHz is a neural audio codec designed for efficient speech tokenization and reconstruction. Unlike traditional codecs that primarily aim to compress audio, MioCodec is optimized for speech representation learning and downstream spoken language modeling.
Key specifications include:
- Token Rate: 25 Hz
- Vocabulary Size: 12,800
- Bitrate: 341 bits per second
- Output Sample Rate: 24 kHz
- Parameters: 132 million
- Vocoder Requirement: None (integrated iSTFTHead decoder)
These characteristics make MioCodec particularly well-suited for large-scale speech language model pretraining and voice transformation tasks.
Disentangled Speech Representation
One of the defining innovations of MioCodec is its explicit separation of speech into two components:
Content Tokens
Content tokens are discrete representations capturing linguistic and phonetic information. They encode what is being said, operating at a low frame rate of 25 Hz. This lower token rate significantly reduces sequence length compared to higher-rate codecs, improving modeling efficiency and reducing training costs.
Global Embeddings
Global embeddings are continuous vectors representing broader acoustic properties such as:
- Speaker identity
- Recording environment
- Microphone characteristics
- Prosody and style
By separating content from acoustic style, MioCodec enables flexible manipulation of speech characteristics while preserving linguistic integrity.
Integrated Waveform Decoder
Many neural codecs require an external vocoder to reconstruct waveforms. MioCodec eliminates this dependency by integrating an iSTFTHead waveform decoder directly into the model architecture.
This end-to-end design offers several advantages:
- Simplified deployment
- Faster inference
- Reduced system complexity
- No need for separate vocoder tuning
The integrated decoder allows direct waveform synthesis at 24 kHz, making MioCodec suitable for both research and production use cases.
Ultra-Low Bitrate Compression at 341 bps
Bitrate efficiency is a major differentiator in neural audio codecs. MioCodec achieves high-fidelity reconstruction at just 341 bits per second, which is significantly lower than many competing codecs operating in the 1–3 kbps range.
This ultra-low bitrate enables:
- Massive dataset compression
- Lower storage costs
- Reduced bandwidth requirements
- Faster SpeechLM training due to shorter token sequences
For researchers working with multilingual datasets spanning tens of thousands of hours, this efficiency can dramatically reduce infrastructure requirements.
Training Methodology
MioCodec-25Hz-24kHz was trained in two structured phases to ensure both spectral accuracy and perceptual realism.
Phase 1: Feature Alignment
The first training stage focuses on spectral and feature reconstruction using:
- Multi-Resolution Mel Spectrogram Loss
- SSL Feature Reconstruction Loss via WavLM-base+
Multiple window sizes ranging from 32 to 2048 ensure detailed frequency modeling across different time scales.
Phase 2: Adversarial Refinement
The second stage introduces adversarial training to improve perceptual quality using:
- Multi-Period Discriminator (MPD)
- Multi-Scale STFT Discriminator (MS-STFTD)
- RMS loss for energy stabilization
This refinement stage reduces artifacts and enhances naturalness, making reconstructed audio perceptually closer to original recordings.
Large-Scale Multilingual Training Data
MioCodec was trained on extensive multilingual datasets covering 11 languages and a wide range of acoustic environments.
Notable datasets include:
- Emilia-YODAS
- MLS-Sidon
- HiFiTTS-2
Approximate training scale:
- Japanese: ~22,500 hours
- English: ~40,000+ hours
- German: ~7,500 hours
- Korean: ~7,300 hours
- French: ~8,450 hours
- Additional languages include Spanish, Italian, Portuguese, Polish, Dutch, and Chinese
This multilingual coverage enhances robustness across accents, speaker identities, and recording conditions.
Zero-Shot Voice Conversion
MioCodec’s disentangled design enables zero-shot voice conversion. By combining:
- Content tokens from a source speaker
- Global embedding from a target speaker
The model can synthesize speech that preserves the linguistic content of the source while adopting the acoustic characteristics of the target.
This functionality supports:
- Voice cloning
- Cross-speaker synthesis
- Accent transfer
- Multilingual style adaptation
All without retraining or fine-tuning the model.
Comparison with Related 25Hz Codecs
MioCodec builds upon the kanade-tokenizer architecture but improves usability and integration.
| Model | Vocoder Required | Sample Rate | Bitrate | Parameters |
|---|---|---|---|---|
| kanade-25hz | Yes | 24 kHz | 341 bps | 118M |
| kanade-12.5hz | Yes | 24 kHz | 171 bps | 120M |
| MioCodec-25Hz-24kHz | No | 24 kHz | 341 bps | 132M |
The removal of an external vocoder simplifies system design while maintaining competitive compression efficiency.
Practical Applications of MioCodec
Spoken Language Model Pretraining
The 25 Hz token rate reduces sequence length, making large-scale SpeechLM training more computationally efficient.
Voice Conversion Systems
Content-style disentanglement enables flexible identity manipulation.
On-Device Speech Applications
Low bitrate and integrated decoding reduce hardware requirements for edge deployment.
Speech Dataset Compression
Massive speech corpora can be compressed without sacrificing perceptual quality.
Why MioCodec Is Important for the Future of Speech AI
As speech AI shifts toward unified multimodal models that treat speech as tokenized sequences similar to text, efficient and modeling-aware codecs become essential.
MioCodec addresses key requirements:
- Compact token sequences
- High perceptual quality
- Multilingual robustness
- Simplified architecture
- Efficient training compatibility
Its combination of low bitrate, 25 Hz tokenization, and integrated waveform synthesis positions it as a strong candidate for next-generation spoken language systems.
Conclusion
MioCodec-25Hz-24kHz represents a meaningful advancement in neural audio codec research. By combining ultra-low bitrate compression at 341 bps, explicit content-style disentanglement, multilingual robustness, and end-to-end waveform synthesis, it provides an efficient and practical foundation for spoken language modeling.
Its 25 Hz token rate strikes a balance between compression efficiency and reconstruction quality, while the integrated iSTFTHead decoder eliminates the need for an external vocoder. These features make MioCodec particularly attractive for SpeechLM pretraining, voice conversion, dataset compression, and scalable speech AI applications.
As large-scale speech models continue to evolve, lightweight and efficient codecs like MioCodec will play a central role in enabling high-quality, resource-efficient spoken language systems.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- TinyClaw by TinyAGI: A Multi-Agent, Multi-Team AI Assistant for 24/7 Automation
- Memori: The Future of SQL-Native Memory Engines for AI and LLM Applications
- The Rise of Distributed AI Systems: Why Scalable Multi-Agent Frameworks Are the Future of Artificial Intelligence
- Building a Real-Life GLaDOS: Inside the Open-Source Project Bringing Valve’s Iconic AI to Life
- MioCodec-25Hz-24kHz: A High-Efficiency Neural Audio Codec for Modern Spoken Language Modeling
2 thoughts on “MioCodec-25Hz-24kHz: A High-Efficiency Neural Audio Codec for Modern Spoken Language Modeling”