
AgentFly is a cutting-edge framework developed by researchers at the Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) to revolutionize how large language models (LLMs) learn and act. It combines the power of reinforcement learning (RL) with language model agents enabling them to go beyond static prompt responses and learn through real-time feedback and experience.
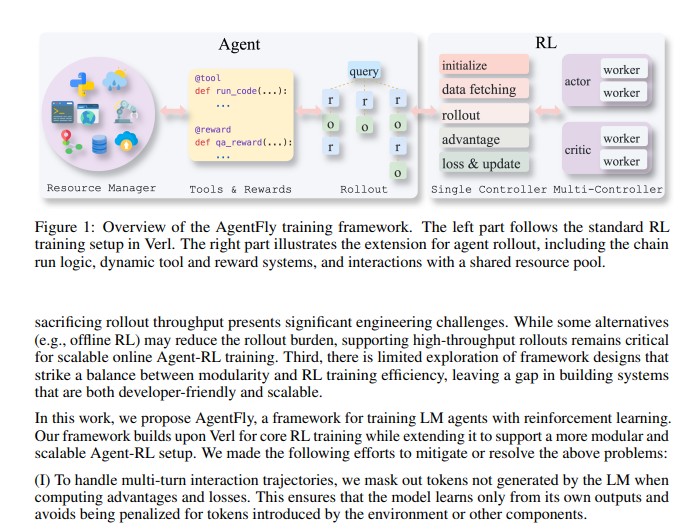
Traditional methods rely heavily on prompt engineering or supervised fine-tuning which limits adaptability and scalability. To overcome these constraints, researchers from the Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) introduced AgentFly – a scalable extensible framework that integrates reinforcement learning (RL) with LM agents.
AgentFly is designed to enhance the autonomy, reasoning ability, and real-world effectiveness of LLM-based agents. It provides a powerful modular architecture for multi-turn interactions, asynchronous execution and efficient environment coordination.
What is AgentFly?
AgentFly is an innovative reinforcement learning framework that enables large language model agents to learn through interaction and feedback. Instead of relying solely on static prompts, AgentFly trains models dynamically by rewarding effective actions and penalizing errors similar to how humans learn from experience.
This framework bridges the gap between language models and reinforcement learning offering developers a flexible system that supports different RL algorithms and training environments. It also introduces several novel design principles such as token-level masking, asynchronous execution and decorator-based interfaces for tools and rewards.
Key Features and Design Innovations
1. Multi-Turn Reinforcement Learning
Unlike standard RL setups that handle single-turn tasks, AgentFly supports multi-turn interactions. Each agent response and observation cycle is part of a longer trajectory allowing the model to learn context-dependent strategies.
To achieve this, the framework applies token-level masking ensuring that only model-generated tokens contribute to learning updates. This prevents external noise such as environment or tool outputs from distorting the agent’s training signal.
2. Modular Tool System
AgentFly abstracts all external interfaces – APIs, environments or functions as tools. These tools are defined using Python decorators making them easy to extend and integrate. Developers can design stateful tools (like code interpreters or browsers) or non-stateful tools (like calculators or web searchers).
This modular approach allows seamless integration of new capabilities enabling agents to interact with diverse systems from coding environments to e-commerce simulations.
3. Asynchronous Execution and Scalability
To handle large-scale, parallel training efficiently, AgentFly introduces an asynchronous rollout system. Each agent runs multiple interaction chains concurrently without blocking others significantly improving throughput.
A centralized resource management system dynamically allocates and recycles environment instances allowing thousands of parallel rollouts – a critical feature for scaling up RL training for large language models.
4. Flexible Reward Design
Defining reward functions in reinforcement learning is notoriously challenging. AgentFly simplifies this with a decorator-based reward system. Rewards can be rule-based, environment-dependent or hybrid allowing fine-grained control over how agent performance is evaluated.
This flexibility ensures that rewards reflect true task success whether in web navigation, scientific experiments or code execution.
Prebuilt Environments and Tools
AgentFly comes with several pre-integrated environments that simulate real-world tasks:
- Code Interpreter – Executes Python code safely and provides output for coding-related reasoning tasks.
- WebShop – Simulates an online shopping website where agents must navigate pages and select products.
- ALFWorld – A household simulation environment for text-based embodied reasoning.
- ScienceWorld – A virtual science lab where agents perform experiments to complete goals.
- Search and Retrieve – Provides access to online search engines and Wikipedia for information retrieval.
These prebuilt environments allow developers to train and evaluate agents in diverse contexts from math problem-solving to e-commerce transactions.
Experimental Insights
The research team evaluated AgentFly using multiple RL algorithms including PPO, REINFORCE++, GRPO and RLOO across Qwen2.5-Instruct models (3B and 7B versions).
The results revealed several key findings:
- All algorithms showed significant reward improvements during training, validating AgentFly’s efficiency.
- Larger models (7B) achieved better performance and learning stability.
- Even smaller models (3B) could successfully learn complex multi-turn behaviors.
- The framework effectively reduced hallucination rates meaning agents became more accurate and consistent over time.
Interestingly, experiments also showed that shorter interaction turns (4-turn settings) led to more stable learning than longer ones (8-turn settings) highlighting the importance of optimizing task granularity in RL agent training.
How AgentFly Accelerates AI Agent Research ?
AgentFly stands out for its balance of modularity and scalability. Unlike earlier frameworks like Verl, RAGEN or RL-Factory, AgentFly natively supports:
- Multi-turn reinforcement learning
- Asynchronous environment execution
- Dynamic tool and reward integration
This makes it a practical solution for researchers and developers building autonomous, reasoning-capable LLM agents. The open-source release also promotes transparency and community-driven innovation.
Conclusion
AgentFly marks a major leap forward in reinforcement learning for language model agents. By combining multi-turn training, modular tool systems and scalable asynchronous execution, it provides a robust foundation for developing intelligent adaptive AI systems.
Whether used for code generation, web automation or real-world decision-making, AgentFly enables LLM agents to learn from their actions improving over time just like humans.
As AI continues to evolve, frameworks like AgentFly will play a critical role in shaping the next generation of autonomous, context-aware and self-improving AI agents.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Unlocking Creativity with Awesome ChatGPT Prompts: The Ultimate Guide for AI Enthusiasts
- LandingAI ADE Python SDK: Streamlining AI-Powered Document Understanding
- The Ultimate #1 Collection of AI Books In Awesome-AI-Books Repository
- Enhancing AI Agent Capabilities with Glean Agent Toolkit: A Complete Guide for Developers
- Mastering Large Language Models: Top #1 Complete Guide to Maxime Labonne’s LLM Course
3 thoughts on “AgentFly: The Future of Reinforcement Learning for Intelligent Language Model Agents”