
Artificial Intelligence has made huge strides in recent years with Large Language Models (LLMs) like GPT, LLaMA and Claude becoming central to research and real-world applications. Yet, one limitation of LLMs is that they rely on the data they were trained on and may not always have up-to-date or domain-specific knowledge. This is where Retrieval-Augmented Generation (RAG) comes in.
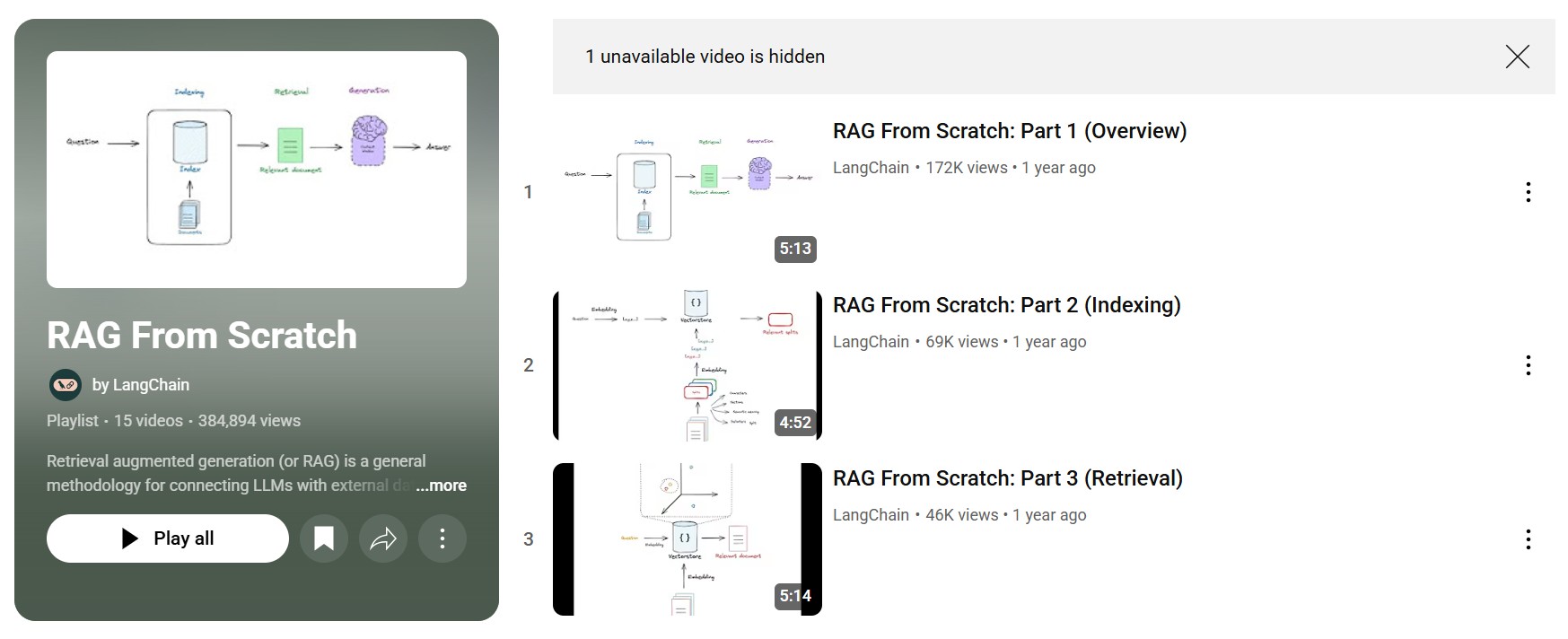
RAG is a powerful methodology that enhances LLMs by connecting them with external data sources. Instead of depending solely on pre-trained knowledge, RAG retrieves relevant context from a database, vector store, or document repository, and uses it to generate more accurate, reliable, and fact-based answers.
To help developers and AI enthusiasts understand this concept step by step, LangChain released a 15-part YouTube series titled “RAG From Scratch.” This series breaks down everything you need to know about RAG from the fundamentals of indexing and retrieval to advanced query translation and retrieval strategies like RAPTOR and ColBERT.
In this blog, we’ll walk through the series, highlight its key insights, and explain why RAG is essential for modern AI applications.
Table of Contents
What is RAG and Why Does It Matter?
At its core, Retrieval-Augmented Generation combines two major steps:
- Retrieval – Fetching relevant information from external sources.
- Generation – Using that retrieved context to produce more accurate, context-aware answers.
For example, if you ask an LLM a question about the latest financial regulations, a standard model may not know the answer if its training data is outdated. But with RAG, the model can first retrieve the most recent regulations from a trusted database and then generate a response grounded in that knowledge.
This approach has several benefits:
- Improved Accuracy – Reduces hallucinations by grounding answers in actual data.
- Domain Adaptability – Connects LLMs with specific knowledge bases, useful for enterprises, research and education.
- Scalability – Can integrate with different retrieval strategies for various use cases.
- Transparency – Makes it easier to trace where information came from.
Breakdown of the RAG From Scratch Series
The LangChain RAG From Scratch playlist contains 15 videos, each focusing on a different aspect of RAG. Here’s a summary of the key lessons:
Part 1: Overview
Introduces the concept of RAG and sets the foundation for the rest of the series.
Part 2: Indexing
Explains how to organize and store data in ways that make retrieval efficient. Vector stores and embeddings play a major role here.
Part 3: Retrieval
Covers the retrieval step, where relevant documents or information are fetched to answer a query.
Part 4: Generation
Shows how retrieved context is combined with the LLM to produce final answers.
Parts 5–9: Query Translation Strategies
- Multi-Query – Breaking down queries into multiple variations for better coverage.
- RAG Fusion – Combining results from multiple queries.
- Decomposition – Splitting complex queries into smaller, manageable parts.
- Step Back – Rephrasing or simplifying queries to get better retrieval.
- HyDE – Using hypothetical document generation to guide retrieval.
Part 10: Routing
Directing queries to the most relevant retriever or database source.
Part 11: Query Structuring
Focuses on how structured queries improve precision in results.
Part 12: Multi-Representation Indexing
Explains how using multiple embeddings for the same data enhances retrieval.
Part 13: RAPTOR
Introduces hierarchical retrieval methods for large-scale knowledge sources.
Part 14: ColBERT
Covers fine-grained retrieval using advanced dense passage retrieval techniques.
Together, these lessons provide a step-by-step roadmap for building effective RAG systems.
How RAG Improves Real-World Applications
RAG is more than a research concept; it has practical applications across industries:
- Enterprise Knowledge Management – Employees can query company policies, technical documentation, or training material in natural language.
- Healthcare – Doctors and researchers can retrieve medical literature and guidelines to support patient care.
- Finance – Analysts can fetch up-to-date reports, compliance rules, and regulations.
- Education – Students can explore textbooks and academic papers through conversational AI.
- Customer Support – Chatbots can pull answers from FAQs, manuals, and support documentation.
By grounding LLM responses in external data, RAG enables organizations to deploy AI with greater confidence.
Final Thoughts
The LangChain “RAG From Scratch” playlist is one of the most comprehensive resources available for understanding RAG. Whether you’re a beginner exploring how LLMs interact with external data or an advanced developer looking to optimize retrieval strategies, this series provides practical, step-by-step guidance.
By mastering indexing, retrieval, query translation, and advanced strategies like RAPTOR and ColBERT, you can build AI systems that are not only intelligent but also accurate, reliable and grounded in real-world knowledge.
👉 You can watch the full playlist here: RAG From Scratch by LangChain
Related Reads
- Determine if Two Strings Are Close in Python – LeetCode75 Explained
- Unique Number of Occurrences in Python – LeetCode75 Explained
- Find the Difference of Two Arrays in Python – LeetCode 75 Explained
- Find Pivot Index in Python – LeetCode75 Explained
- Transformers, Reasoning & Beyond: A Powerful Deep Dive with Antonio Gulli
Resources
LangChain Documentation
https://python.langchain.com/docs/
Vector Databases for RAG
- Pinecone: https://www.pinecone.io/learn/retrieval-augmented-generation/
- FAISS (Meta AI): https://github.com/facebookresearch/faiss
4 thoughts on “RAG From Scratch: A Complete Guide to Retrieval-Augmented Generation”