OpenAI Evals: The Framework Transforming LLM Evaluation and Benchmarking
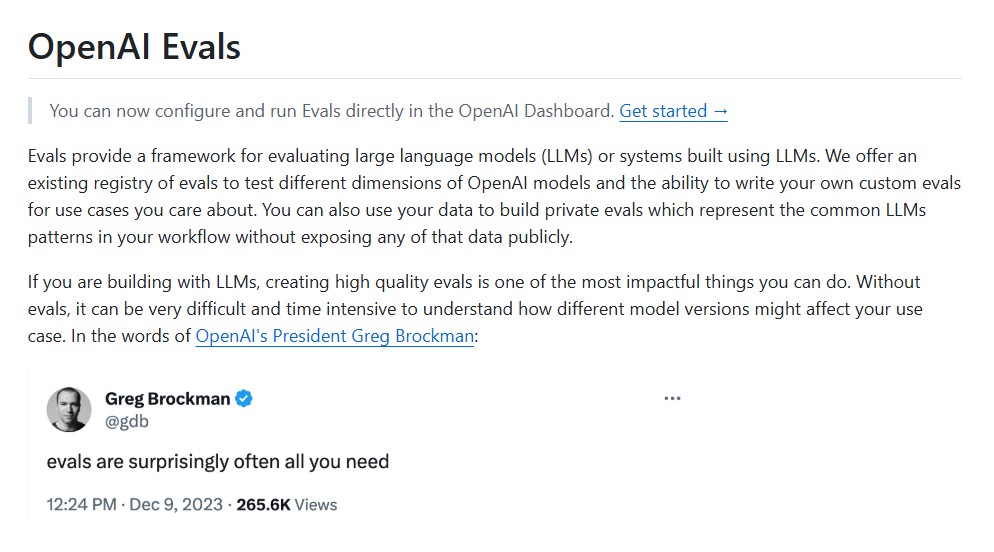
As large language models (LLMs) continue to reshape industries from education and healthcare to marketing and software development – the need for reliable evaluation methods has never been greater. With new models constantly emerging, developers and researchers require a standardized system to test, compare and understand model performance across real-world scenarios. This is where OpenAI … Read more