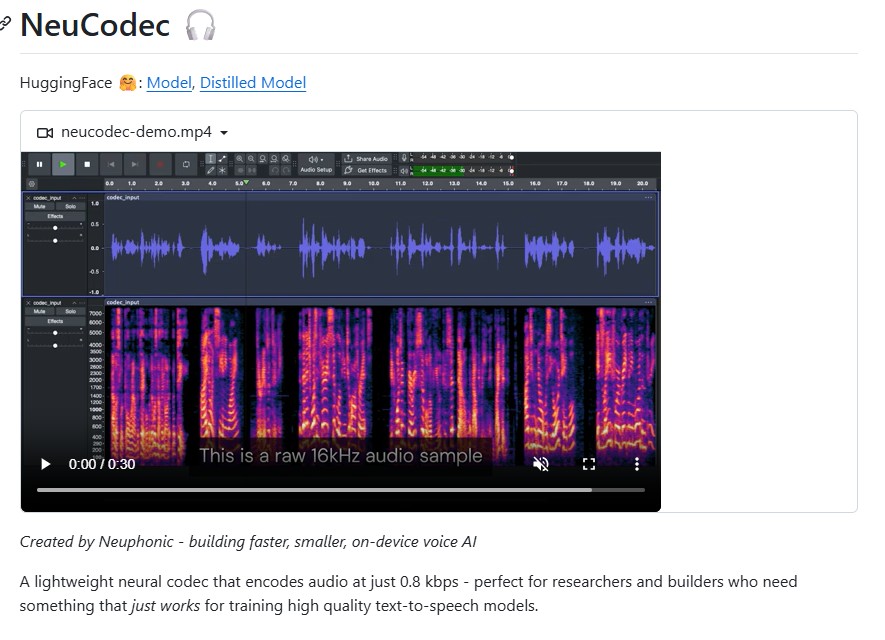
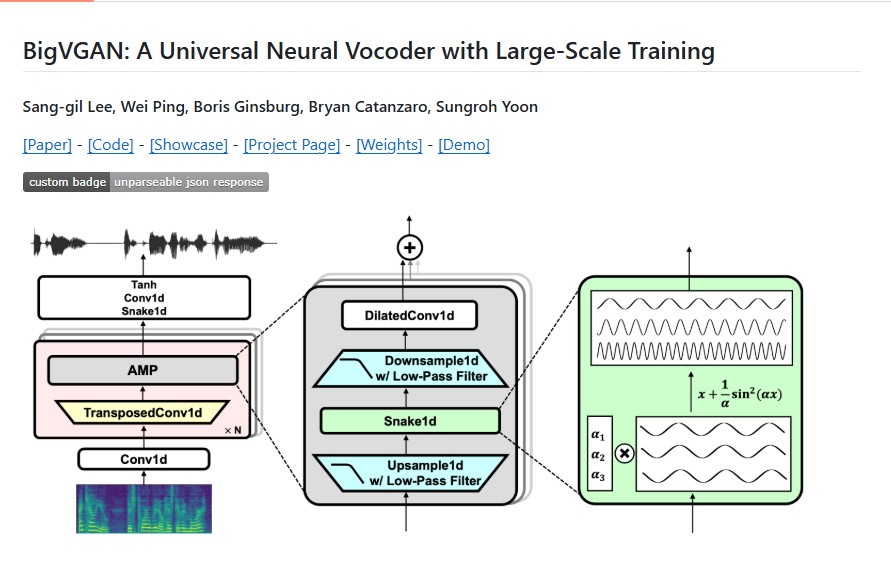
TinyClaw by TinyAGI: A Multi-Agent, Multi-Team AI Assistant for 24/7 Automation

TinyClaw is a multi-agent orchestration system designed to run AI teams 24/7 across multiple channels. Artificial intelligence is rapidly evolving beyond single chatbot interactions. The next generation is collaborative AI systems where multiple specialized agents work together, operate continuously, and manage tasks autonomously. TinyClaw, developed by TinyAGI, represents this shift. It is an open-source multi-agent, … Read more