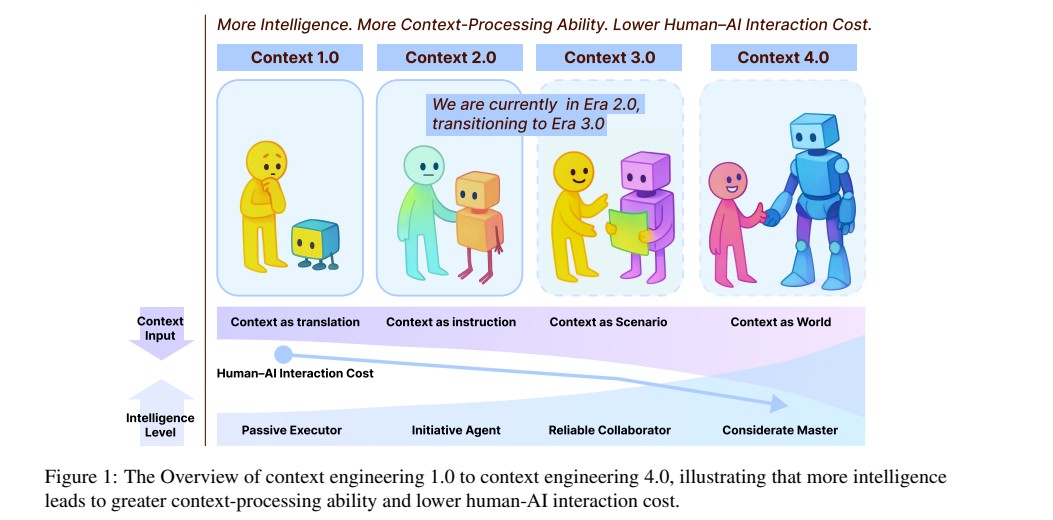
Omnilingual ASR: Meta’s Breakthrough in Multilingual Speech Recognition for 1600+ Languages
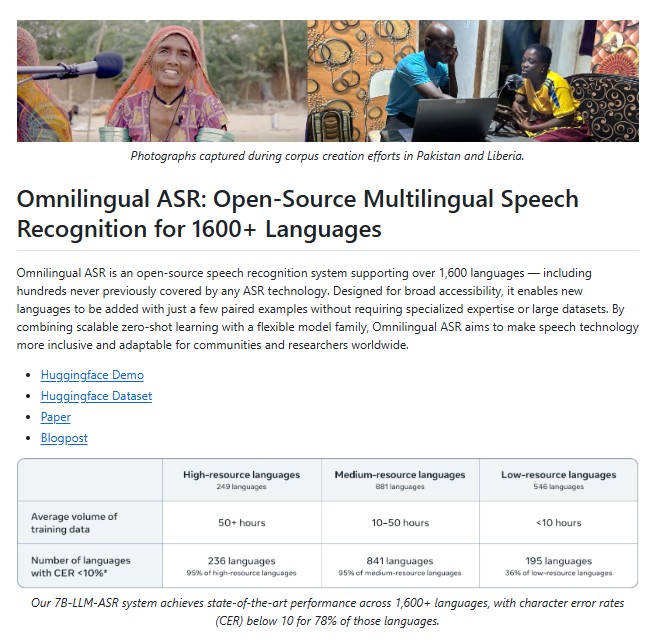
In an increasingly connected world, speech technology plays a vital role in bridging communication gaps across languages and cultures. Yet, despite rapid progress in Automatic Speech Recognition (ASR), most commercial systems still cater to only a few dozen major languages. Billions of people who speak lesser-known or low-resource languages remain excluded from the benefits of … Read more