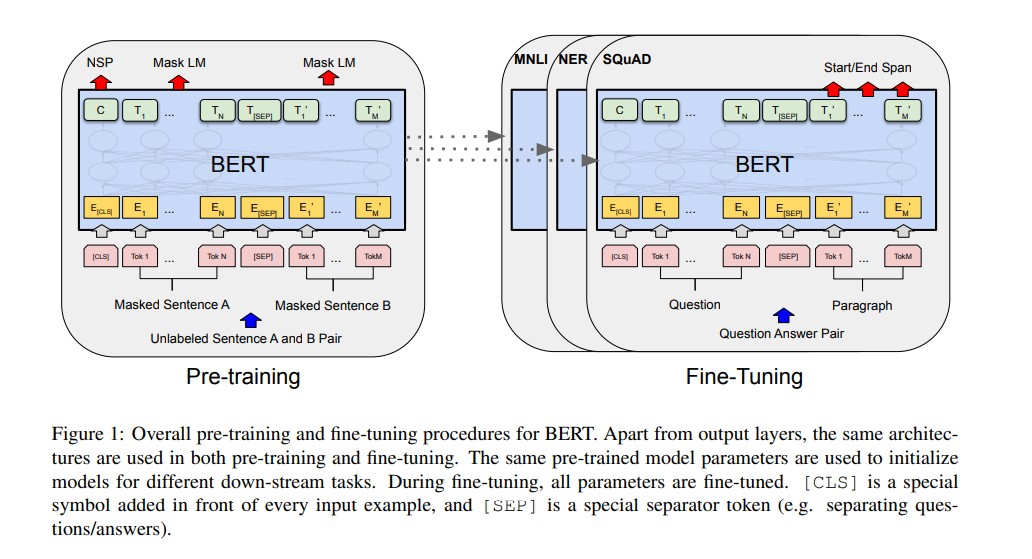
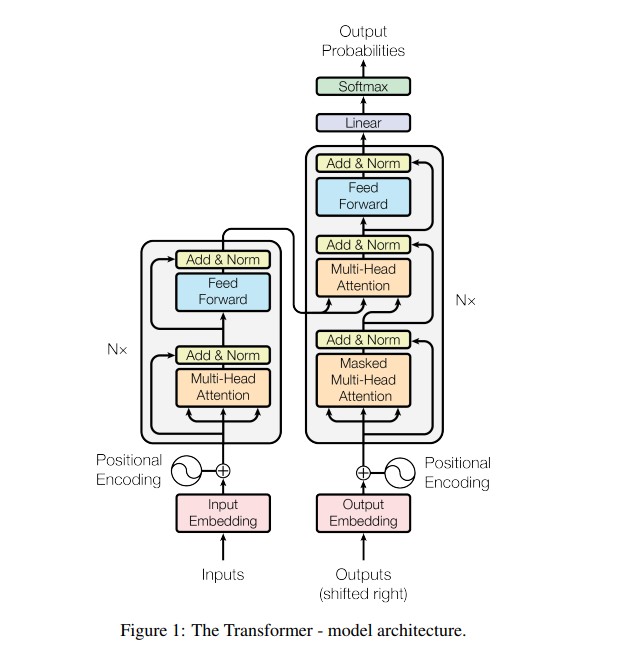
Motif-2-12.7B: A Breakthrough in Efficient Large Language Model Architecture

The rapid evolution of large language models (LLMs) has redefined how industries approach automation, content creation, data analysis, and decision-making. While tech giants have been scaling models with billions of parameters to achieve superior performance, an equally important challenge has emerged: how do we make LLMs more efficient without compromising their reasoning ability and accuracy? … Read more