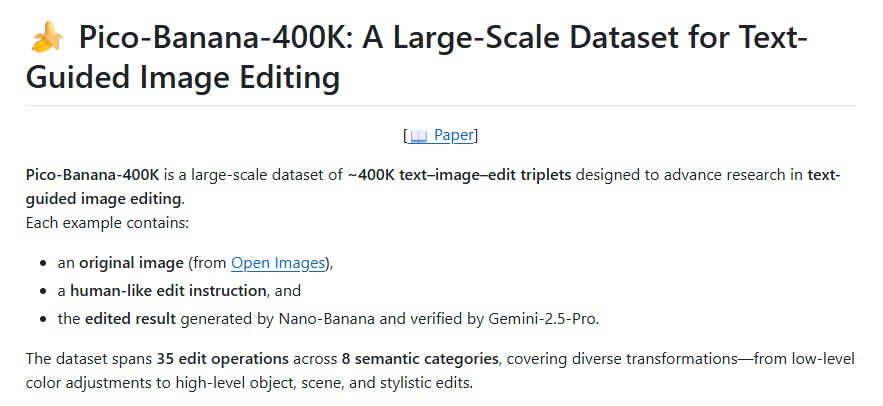
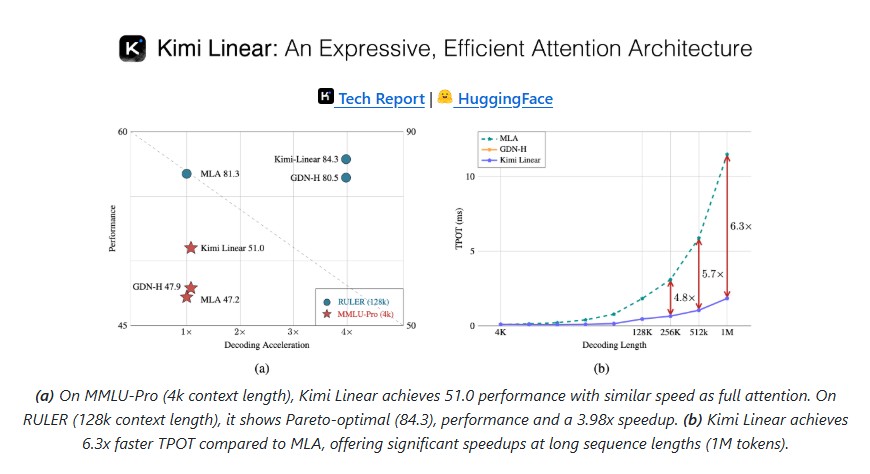
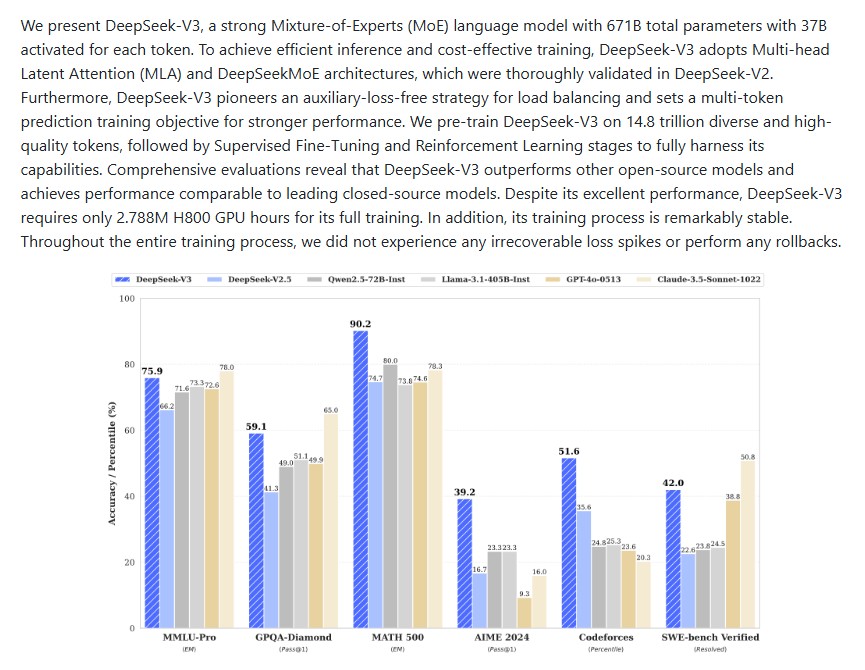
Concerto: How Joint 2D-3D Self-Supervised Learning Is Redefining Spatial Intelligence

The world of artificial intelligence is rapidly evolving and self-supervised learning has become a driving force behind breakthroughs in computer vision and 3D scene understanding. Traditional supervised learning relies heavily on labeled datasets which are expensive and time-consuming to produce. Self-supervised learning, on the other hand, extracts meaningful patterns without manual labels allowing models to … Read more