
The evolution of artificial intelligence has reached a stage where models are no longer limited to understanding text or images independently. The emergence of multimodal AI systems capable of processing and reasoning across multiple types of data has transformed how machines interpret the world. Yet, most existing multimodal models remain passive observers, unable to act or interact with tools to enhance their reasoning. The research paper “DeepEyesV2: Toward Agentic Multimodal Model” introduces a major step forward, presenting a framework that enables AI models to become agentic, meaning they can proactively use external tools such as code execution and web search to refine their understanding and solve complex problems.
This blog explores the key innovations, methodology, and results of DeepEyesV2, shedding light on how it paves the way for a new generation of agentic multimodal reasoning systems.
What Is an Agentic Multimodal Model?
An agentic multimodal model goes beyond passive perception. It doesn’t merely describe what it sees or reads – it takes action to improve its reasoning. Such models can actively use tools to manipulate data, retrieve external knowledge, and combine these findings into coherent, evidence-based reasoning.
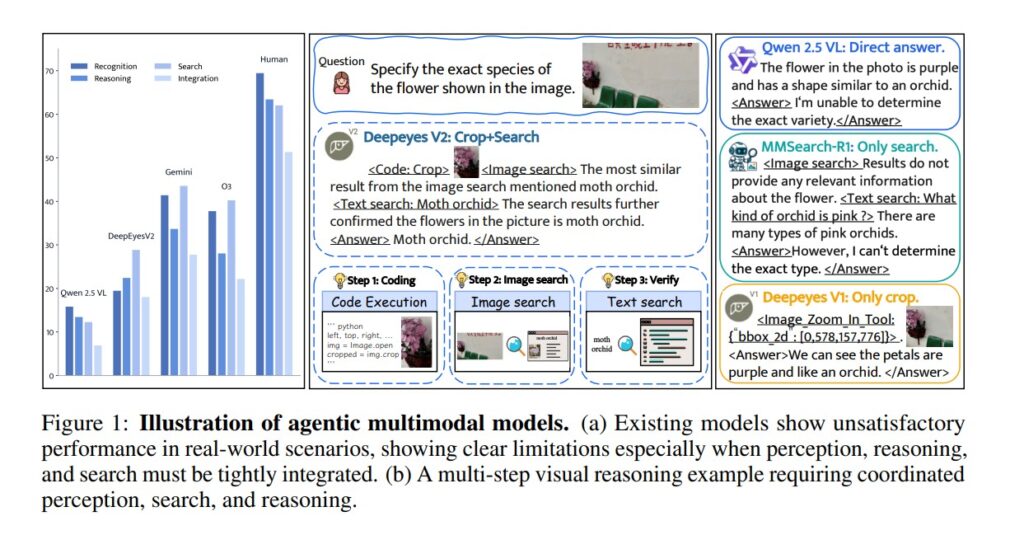
For instance, when asked to identify a flower species from an image, an agentic model like DeepEyesV2 first crops the image to isolate the flower, then performs a web search to compare visual results and determine the correct species. This active engagement allows the model to verify its conclusions, reduce hallucinations, and enhance accuracy capabilities that traditional multimodal systems lack.
The Core of DeepEyesV2
DeepEyesV2, developed by researchers at Xiaohongshu Inc., represents a new generation of agentic multimodal large language models (MLLMs). It is built upon the foundation of DeepEyes but significantly enhances tool-use integration and reasoning flexibility.
Unlike models that only describe images or texts, DeepEyesV2 can:
- Invoke external tools dynamically, such as executing Python code or searching the web.
- Integrate outputs from these tools into its reasoning loop.
- Adapt its strategy—using perception for visual tasks, computation for reasoning, and search for information-intensive questions.
This structure allows DeepEyesV2 to operate as a self-improving reasoning system capable of handling real-world problems that require combining multiple skills.
Two-Stage Training Process: Cold Start and Reinforcement Learning
The study reveals that direct reinforcement learning (RL) alone is insufficient to teach models how to use tools effectively. To address this, DeepEyesV2 introduces a two-stage training pipeline:
1. Cold-Start Stage
In this stage, the model learns fundamental patterns of tool use through supervised fine-tuning (SFT) on curated datasets. These datasets include tasks from perception, reasoning, and search domains as well as long chain-of-thought (CoT) examples. The cold start enables the model to understand when and how to invoke tools like code or web queries.
2. Reinforcement Learning Stage
Once the model establishes basic tool-use behavior, reinforcement learning refines it. The RL stage allows the model to learn adaptive decision-making knowing when to use a tool and when not to. This results in more efficient, context-aware reasoning. The study uses simple yet effective rewards focused on accuracy and format correctness, ensuring clean, verifiable model outputs.
RealX-Bench: A New Benchmark for Real-World Reasoning
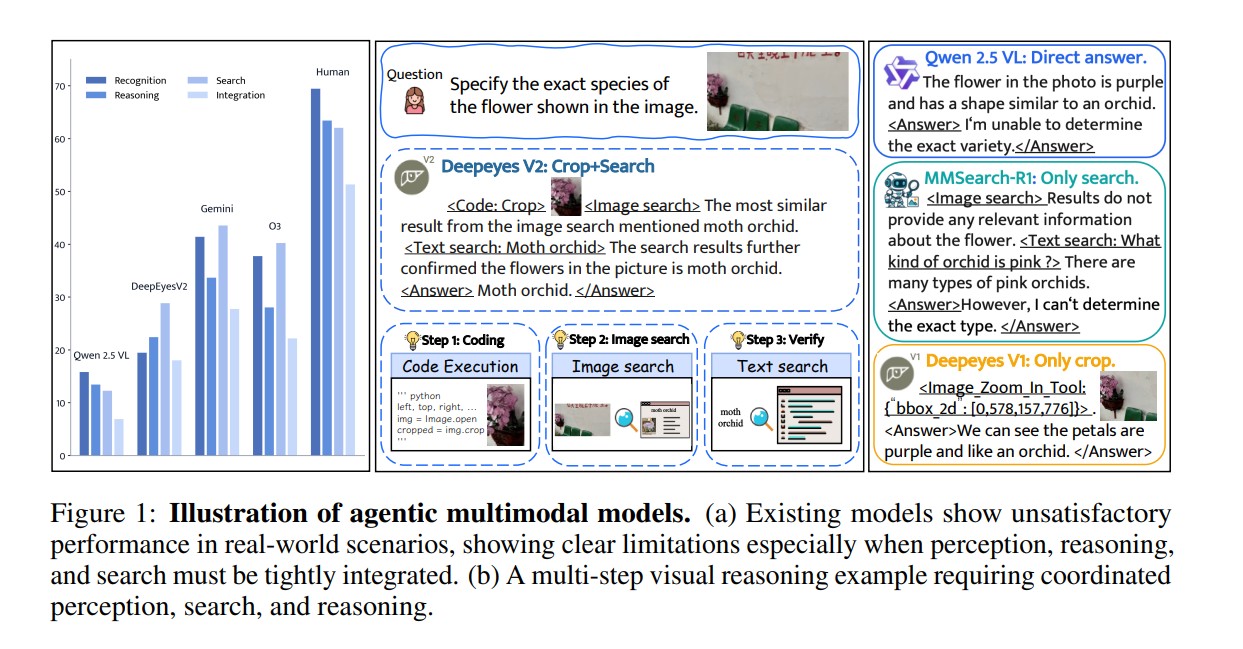
To evaluate DeepEyesV2’s capabilities, the researchers introduced RealX-Bench, a comprehensive benchmark that measures a model’s ability to integrate perception, search, and reasoning. Unlike previous benchmarks that focus on a single skill, RealX-Bench tests the model’s ability to coordinate all three abilities simultaneously just like humans do when solving complex problems.
The benchmark covers five major domains: daily life, media, sports, knowledge, and games. It includes 300 real-world question–answer pairs that require fine-grained observation, logical reasoning and online evidence gathering. Human performance on this benchmark remains significantly higher than AI systems, indicating room for future growth, but DeepEyesV2 shows impressive progress.
Key Results and Findings
DeepEyesV2 achieves substantial improvements over both open-source and proprietary models in diverse categories:
- Real-world understanding: Surpasses larger models like Qwen2.5-VL-32B through effective tool integration.
- Mathematical reasoning: Outperforms other reasoning-focused models with a +7.1% improvement on MathVerse benchmark.
- Search-based tasks: Reaches 63.7% accuracy on MMSearch, significantly higher than MMSearch-R1’s 53.8%.
These results demonstrate that dynamic tool invocation directly enhances reasoning accuracy and enables the model to solve tasks that standard multimodal models cannot handle effectively.
Another critical finding is that reinforcement learning improves tool efficiency. After training, DeepEyesV2 doesn’t overuse tools – it learns when tool invocation is necessary and when internal reasoning suffices. This balance between autonomy and resourcefulness is what makes DeepEyesV2 genuinely agentic.
Implications for the Future of AI
DeepEyesV2 marks a milestone in the evolution of multimodal AI systems. By integrating perception, computation, and information retrieval, it represents a shift from reactive intelligence to proactive problem-solving. The study also demonstrates how structured datasets and staged learning can cultivate advanced reasoning behaviors in large models.
As AI continues to expand its role in fields like research, healthcare, education and business analytics, agentic multimodal systems will play a key role in:
- Automating complex reasoning tasks requiring real-time data verification.
- Enhancing transparency through verifiable tool outputs.
- Reducing hallucinations by grounding reasoning in external evidence.
DeepEyesV2’s open research contributions, including the RealX-Bench benchmark and detailed training methodologies, provide valuable resources for the AI community to build even more advanced models in the future.
Conclusion
DeepEyesV2 is more than just an incremental upgrade – it is a paradigm shift in multimodal AI development. By combining structured learning, tool invocation, and reinforcement-based adaptability, it sets a foundation for creating autonomous, reasoning-driven systems that can think, act, and verify like humans. The integration of perception, search and reasoning within a single model represents a key step toward true artificial agency.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- CALM: Revolutionizing Large Language Models with Continuous Autoregressive Learning
- Supervised Reinforcement Learning: A New Era of Step-Wise Reasoning in AI
- Context Engineering 2.0: Redefining Human–Machine Understanding
- OpenAI Evals: The Framework Transforming LLM Evaluation and Benchmarking
- Skyvern: The Future of Browser Automation Powered by AI and Computer Vision
1 thought on “DeepEyesV2: The Next Leap Toward Agentic Multimodal Intelligence”