The field of artificial intelligence has entered a transformative phase – one defined by scale, specialization and accessibility. As the demand for larger and more capable language models grows, the challenge lies not only in achieving state-of-the-art performance but also in doing so efficiently and sustainably. DeepSeek-AI’s latest release, DeepSeek-V3 redefines what is possible at the intersection of scale, efficiency and open-source collaboration.
DeepSeek-V3 is a Mixture-of-Experts (MoE) language model with 671 billion total parameters of which 37 billion are activated per token. It combines architectural innovation, precision optimization and intelligent training strategies to deliver results that rival and in many areas, surpass leading closed-source systems.
With groundbreaking features like Multi-Token Prediction (MTP), auxiliary-loss-free load balancing and FP8 precision training, DeepSeek-V3 represents a major milestone in efficient large-model design. It demonstrates that world-class AI performance can be achieved at a fraction of traditional computational costs all while remaining open and accessible to the research community.
A New Generation of Mixture-of-Experts Architecture
At its foundation, DeepSeek-V3 builds upon the success of DeepSeek-V2 enhancing it with refined architectures such as Multi-Head Latent Attention (MLA) and a DeepSeekMoE framework. These designs allow for precise load distribution across experts while reducing redundancy and improving inference speed.
The standout innovation lies in its auxiliary-loss-free load balancing strategy. Traditional MoE models rely on auxiliary losses to maintain balanced workloads among experts which can often reduce training efficiency. DeepSeek-V3 eliminates this dependency maintaining balanced training dynamics without sacrificing performance.
Additionally, DeepSeek-V3 introduces a Multi-Token Prediction (MTP) objective. Instead of predicting a single token at a time, the model learns to predict multiple tokens simultaneously. This approach enhances predictive accuracy and supports speculative decoding, leading to faster inference and lower latency.
The result is a model that maintains superior accuracy, reasoning ability and throughput while operating with remarkable efficiency.
Training Efficiency and Hardware Co-Design
One of DeepSeek-V3’s greatest achievements is its unmatched training efficiency. Despite its massive scale 671 billion parameters – the model was trained using only 2.788 million H800 GPU hours far less than what most frontier models require.
This efficiency is made possible through FP8 mixed precision training, a groundbreaking approach that optimizes memory usage and computational throughput without compromising numerical stability. DeepSeek-AI’s engineers co-designed the model architecture, software framework and hardware execution pipeline to ensure maximum overlap between computation and communication across nodes.
The result is near-perfect computation-communication overlap allowing the system to utilize GPU clusters with minimal idle time. These optimizations enable DeepSeek-V3 to scale up while remaining cost-effective and energy efficient demonstrating how algorithmic and systems-level co-design can lead to sustainable large-scale AI.
Knowledge Distillation from DeepSeek-R1
Another defining aspect of DeepSeek-V3’s training pipeline is its post-training distillation from DeepSeek-R1, a model renowned for its strong reasoning and chain-of-thought capabilities.
Through this process, the reasoning patterns of R1 particularly verification and reflection behaviors are distilled into DeepSeek-V3. This allows the model to emulate R1’s structured reasoning while maintaining more concise controlled outputs.
In effect, DeepSeek-V3 inherits R1’s deep logical capabilities while retaining the speed and adaptability of a standard language model. This fusion creates a system capable of delivering accurate, grounded and contextually rich responses making it highly versatile across academic, professional and creative applications.
Evaluation Results: Outperforming Open and Closed Models
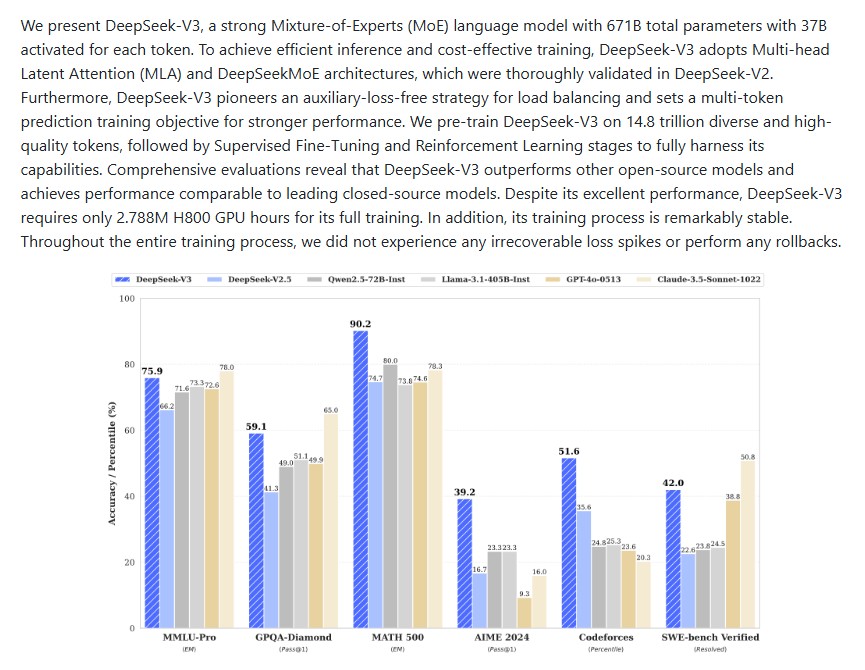
Comprehensive evaluations show that DeepSeek-V3 sets a new standard among open-source large language models. It not only outperforms its predecessor but also competes closely with leading proprietary models such as GPT-4o, Claude 3.5 Sonnet and LLaMA 3.1.
On benchmarks like MMLU-Pro, BBH and DROP, DeepSeek-V3 consistently achieves top-tier scores:
- MMLU (5-shot): 87.1%
- MMLU-Pro: 64.4%
- DROP (3-shot F1): 89.0%
- HumanEval (Code, 0-shot): 65.2%
- MATH (4-shot EM): 61.6%
- AIME 2024 (Pass@1): 39.2%
- MATH-500 (EM): 90.2%
In the Chat Model category, DeepSeek-V3 demonstrates particularly strong reasoning, coding, and mathematical performance:
- HumanEval-Mul (Code): 82.6%
- LiveCodeBench (Pass@1): 37.6%
- MATH-500 (EM): 90.2%
- CNMO 2024 (Math): 43.2%
- C-Eval (Chinese Benchmark): 86.5%
These results affirm that DeepSeek-V3 not only excels in English-language reasoning but also performs impressively in multilingual, mathematical and coding benchmarks showcasing its global and technical versatility.
Open Access and Local Deployment
DeepSeek-V3 is designed with flexibility and accessibility at its core. The model is fully open-source under the MIT License (for code) and a dedicated Model License (for weights) supporting commercial use.
The model weights both Base and Chat versions are available on Hugging Face offering 128K context length and compatibility with multiple inference frameworks.
Developers can run DeepSeek-V3 locally using several supported frameworks, including:
- SGLang: Optimized for FP8 and BF16 inference with Multi-Token Prediction support.
- LMDeploy: High-performance offline and online inference solution.
- TensorRT-LLM: Supports INT4, INT8 and BF16 quantization for NVIDIA GPUs.
- vLLM: Efficient pipeline parallelism for multi-node inference.
- LightLLM: Lightweight deployment for multi-node and mixed precision inference.
- AMD GPUs & Huawei Ascend NPUs: Fully compatible via SGLang and MindIE frameworks.
Through this ecosystem, DeepSeek-V3 can be run on a wide range of hardware from high-end GPU clusters to AMD and Huawei AI accelerators making it one of the most accessible and scalable open models ever released.
Real-World Applications
DeepSeek-V3’s capabilities make it suitable for a diverse range of applications, including:
- Code generation and debugging — outperforming other open models in programming tasks.
- Mathematical reasoning — ideal for STEM research, education and data analysis.
- Multilingual dialogue systems — offering consistent quality across English and Chinese benchmarks.
- Knowledge retrieval and analysis — leveraging long-context comprehension for document summarization and retrieval-augmented generation.
- Enterprise AI deployment — providing open-source flexibility for organizations seeking customizable AI solutions.
Its combination of performance, scalability, and openness positions DeepSeek-V3 as a cornerstone for the next wave of enterprise-grade and research-driven AI systems.
Open Collaboration and Responsible AI
DeepSeek-AI’s mission extends beyond building high-performance models – it’s about democratizing AI. By releasing DeepSeek-V3 under permissive licenses, the team empowers developers, researchers and organizations to contribute, modify and deploy the model freely.
This approach fosters transparency, collaboration and accountability ensuring that the development of powerful AI systems remains in the hands of the broader community rather than being confined to closed ecosystems.
Moreover, DeepSeek-AI emphasizes responsible scaling, showcasing that massive models can be trained efficiently and sustainably through thoughtful architecture and optimization rather than sheer computational force.
Conclusion
DeepSeek-V3 is more than an AI model – it is a landmark in the evolution of open-source intelligence. With 671 billion parameters, advanced MoE architecture, and innovations like Multi-Token Prediction and FP8 precision training, it demonstrates that scale and efficiency can coexist without compromise.
Its competitive performance across benchmarks, multilingual strength, and coding mastery position it among the most capable open models ever released. Beyond performance, its open-access licensing and hardware versatility make it a blueprint for the future of AI – powerful, efficient and open to all.
As AI continues to advance, DeepSeek-V3 serves as proof that open innovation remains the key to accelerating progress responsibly, sustainably and inclusively.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Krea Realtime 14B: Redefining Real-Time Video Generation with AI
- LongCat-Video: Meituan’s Groundbreaking Step Toward Efficient Long Video Generation with AI
- HunyuanWorld-Mirror: Tencent’s Breakthrough in Universal 3D Reconstruction
- MiniMax-M2: The Open-Source Revolution Powering Coding and Agentic Intelligence
- MLOps Basics: A Complete Guide to Building, Deploying and Monitoring Machine Learning Models
2 thoughts on “DeepSeek-V3: Pioneering Large-Scale AI Efficiency and Open Innovation”