The evolution of Automatic Speech Recognition (ASR) has reshaped how humans interact with technology. From dictation tools and live transcription to smart assistants and media captioning, ASR technology continues to bridge the gap between speech and digital communication. However, achieving real-time, high-accuracy transcription often comes at the cost of heavy computational requirements until now.
Enter Distil-Whisper, an innovation from Hugging Face that revolutionizes the ASR landscape. Based on OpenAI’s Whisper, Distil-Whisper retains nearly the same performance while being six times faster and 49% smaller, making it ideal for real-time and resource-constrained applications.
In this blog, we explore how Distil-Whisper works, its key advantages, usage and why it’s the perfect lightweight alternative for modern English speech recognition.
What Is Distil-Whisper?
Distil-Whisper is a distilled version of OpenAI’s Whisper model, designed specifically for English speech recognition. Developed by Hugging Face, this model achieves almost identical transcription accuracy to the original Whisper while offering 6x faster inference speed and requiring half the storage and compute resources.
The model family includes multiple versions such as:
- distil-large-v3 (recommended for most applications)
- distil-large-v2
- distil-medium.en
- distil-small.en
Among these, distil-large-v3 provides the best balance between speed, accuracy, and compatibility across Whisper-based libraries.
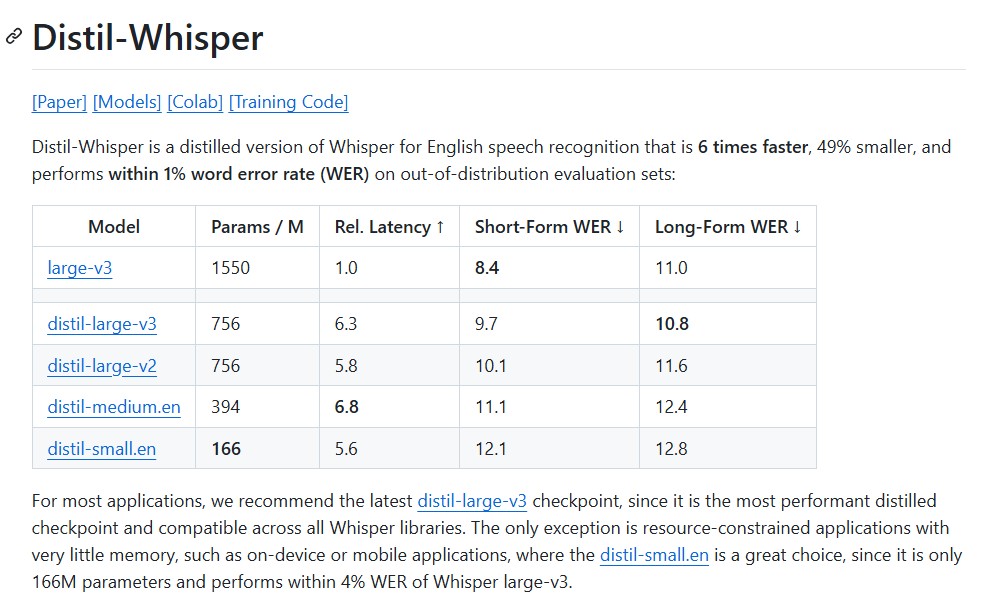
Quick Comparison
| Model | Parameters (M) | Speed (↑) | Short-Form WER ↓ | Long-Form WER ↓ |
| large-v3 | 1550 | 1.0x | 8.4 | 11.0 |
| distil-large-v3 | 756 | 6.3x | 9.7 | 10.8 |
| distil-medium.en | 394 | 6.8x | 11.1 | 12.4 |
| distil-small.en | 166 | 5.6x | 12.1 | 12.8 |
These results show that Distil-Whisper achieves within 1% Word Error Rate (WER) of Whisper’s large models while drastically improving efficiency.
Why Distil-Whisper Matters ?
Whisper, while powerful, requires significant computational resources and is slow for real-time applications or mobile devices. Distil-Whisper bridges this gap by compressing Whisper’s architecture through knowledge distillation, enabling faster and smaller models without compromising quality.
Here’s why it stands out:
1. 6x Faster Inference
Distil-Whisper delivers up to 6.3x faster processing than Whisper, enabling real-time transcription for live streaming, meetings or call centers.
2. 49% Smaller Model Size
With nearly half the parameters of Whisper, it reduces memory and storage requirements, making it suitable for on-device AI and mobile speech apps.
3. Near-Identical Accuracy
Despite the reduction in size, the model maintains less than 1% accuracy loss, ensuring performance that’s practically on par with Whisper’s large models.
4. Lower Latency and Hallucination Rate
Distil-Whisper exhibits fewer transcription errors and reduces hallucinations by 2%, leading to more reliable outputs in noisy environments.
5. Commercially Friendly MIT License
Released under the MIT License, developers and companies can freely use Distil-Whisper for commercial purposes, unlike many restricted ASR systems.
How Distil-Whisper Works ?
Distil-Whisper leverages knowledge distillation, a training technique where a smaller “student” model learns from a larger, pre-trained “teacher” model — in this case, OpenAI’s Whisper.
Step-by-Step Distillation Process
- Encoder Copying and Freezing:
The entire encoder from Whisper is copied and frozen to retain its robust speech feature extraction capabilities. - Decoder Reduction:
Instead of using all decoder layers, Distil-Whisper keeps only two — the first and last drastically reducing model size while preserving contextual understanding. - Training with Pseudo-Labeled Data:
The model is trained on 22,000 hours of pseudo-labeled audio covering over 18,000 speakers and 10 diverse domains. - Error Filtering:
Data samples where Whisper produces hallucinated or incorrect transcriptions are filtered out using WER-based filters, improving robustness. - Loss Optimization:
Distil-Whisper minimizes both KL divergence (to align with Whisper’s outputs) and cross-entropy loss (to improve linguistic accuracy).
This process results in a smaller yet powerful model capable of fast and accurate transcription across multiple English datasets.
Installation and Setup
Distil-Whisper is integrated directly into the Hugging Face Transformers library (version 4.35 or later). Installation is simple:
pip install --upgrade transformers accelerate datasets
Short-Form Transcription (Under 30 Seconds)
For short clips, Distil-Whisper processes entire audio samples at once:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
).to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline("automatic-speech-recognition", model=model, tokenizer=processor.tokenizer, feature_extractor=processor.feature_extractor, device=device)
result = pipe("audio.mp3")
print(result["text"])
This setup offers real-time transcription for clips under 30 seconds with remarkable speed.
Long-Form Transcription (Over 30 Seconds)
Distil-Whisper supports two types of long-form transcription algorithms:
1. Sequential Long-Form
- Designed for maximum accuracy.
- Processes audio in a buffered sliding window.
- Recommended for large transcription batches.
2. Chunked Long-Form
- Prioritizes speed over accuracy.
- Up to 9x faster than sequential processing.
- Ideal for single long audio files or streaming data.
For most practical applications, distil-large-v3 balances both accuracy and latency effectively.
Speculative Decoding: 2x Faster Whisper
Distil-Whisper also functions as an assistant model for OpenAI’s Whisper in a setup called speculative decoding. In this approach:
- Whisper acts as the teacher model.
- Distil-Whisper acts as a student assistant.
This method doubles inference speed while guaranteeing identical transcription results to Whisper. It’s ideal for developers who want faster pipelines without accuracy trade-offs.
Advanced Optimizations
For additional performance, developers can leverage:
Flash Attention 2: For optimized GPU memory and faster inference.
pip install flash-attn --no-build-isolation
Torch Scaled-Dot Product Attention (SDPA): Converts the model into a more efficient “BetterTransformer.”
pip install --upgrade optimum model = model.to_bettertransformer()
These optimizations make Distil-Whisper capable of running smoothly even on mid-tier hardware.
Integration and Compatibility
Distil-Whisper integrates seamlessly with multiple frameworks and libraries, including:
| Library | distil-small.en | distil-medium.en | distil-large-v2 |
| OpenAI Whisper | ✅ | ✅ | ✅ |
| Whisper.cpp | ✅ | ✅ | ✅ |
| Transformers.js | ✅ | ✅ | ✅ |
| Candle (Rust) | ✅ | ✅ | ✅ |
This wide compatibility ensures developers can deploy Distil-Whisper across Python, JavaScript, and even Rust environments effortlessly.
Real-World Applications
Distil-Whisper’s compactness and speed make it suitable for diverse applications:
- Real-Time Captioning: Fast transcription for streaming platforms or classrooms.
- Call Centers: On-device ASR for customer service analytics.
- Mobile Apps: Lightweight ASR for virtual assistants and note-taking.
- Media Production: Automated subtitling for videos and podcasts.
- Accessibility Tools: Speech-to-text systems for the hearing-impaired.
Its robustness to background noise and low WER performance make it highly adaptable across environments.
Conclusion
Distil-Whisper by Hugging Face is a monumental step forward in the evolution of speech recognition. By distilling the power of OpenAI’s Whisper into a smaller, faster, and equally accurate model, it bridges the gap between cutting-edge performance and real-world usability.
For developers and enterprises alike, Distil-Whisper represents the future of efficient, high-speed, and accurate speech recognition. With its open-source MIT license and compatibility across popular libraries, it empowers everyone from hobbyists to industry leaders to build scalable, voice-driven solutions with ease.
Whether you’re developing mobile voice applications, transcription services, or real-time captioning tools, Distil-Whisper ensures that high-performance ASR is no longer limited by computational constraints.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Whisper by OpenAI: The Revolution in Multilingual Speech Recognition
- Omnilingual ASR: Meta’s Breakthrough in Multilingual Speech Recognition for 1600+ Languages
- LEANN: The Bright Future of Lightweight, Private, and Scalable Vector Databases
- Reducing Hallucinations in Vision-Language Models: A Step Forward with VisAlign
- DeepEyesV2: The Next Leap Toward Agentic Multimodal Intelligence
2 thoughts on “Distil-Whisper: Faster, Smaller, and Smarter Speech Recognition by Hugging Face”