In the fast-growing field of speech and language AI, IBM continues to make strides with its Granite model family , a suite of open enterprise-grade AI models that combine accuracy, safety and efficiency. The latest addition to this ecosystem, Granite-Speech-3.3-8B marks a significant milestone in automatic speech recognition (ASR) and speech translation (AST) technology.
Released in June 2025 and available on Hugging Face, this model brings multilingual capabilities, modular architecture and enhanced safety to the world of speech-language modeling. Designed for enterprise applications, it offers both robust transcription accuracy and secure multimodal integration, a combination that many AI systems still struggle to balance.
In this blog, we’ll explore the architecture, training data, capabilities, performance and ethical considerations of Granite-Speech-3.3-8B and why it’s positioned as one of the most capable open speech models for real-world use.
What Is Granite-Speech-3.3-8B?
Granite-Speech-3.3-8B is a compact yet powerful 8.65-billion-parameter model developed by IBM Research as part of the Granite model suite. It is designed for automatic speech recognition (ASR) and automatic speech translation (AST) converting speech into text and translating between multiple languages with high precision.
Unlike end-to-end integrated systems that process speech and language simultaneously, Granite-Speech follows a two-pass architecture:
- Pass One: Converts raw audio into transcribed text.
- Pass Two: Feeds the transcribed text into IBM’s Granite-3.3-8B-Instruct large language model for reasoning, translation or downstream text processing.
This modular design makes the system safer and more transparent ensuring that audio interpretation is separated from language reasoning, minimizing unintended interactions or hallucinations.
Supported Languages and Capabilities
Granite-Speech-3.3-8B supports six languages, with a primary focus on English, French, German, Spanish and Portuguese and partial support for English-to-Japanese and English-to-Mandarin translation.
The model excels in:
- Speech-to-Text (ASR): Accurate transcription of audio input into written form.
- Speech Translation (AST): Translating spoken content between multiple languages.
- Text-only tasks: When no audio is present, it defers to the underlying Granite language model for standard LLM functionality.
This flexibility allows Granite-Speech to act as both a speech-enabled AI assistant and a multilingual transcription tool depending on the context.
A Deep Dive into the Architecture
Granite-Speech-3.3-8B’s architecture represents a hybrid of speech processing and large language modeling – a system that bridges acoustic understanding with textual reasoning. It is composed of four major components:
1. Speech Encoder
The first stage of the model is a 16-layer Conformer encoder trained with Connectionist Temporal Classification (CTC) on character-level targets.
Key specifications:
- Input dimension: 160 (80 log-mels × 2)
- Hidden size: 1024
- Attention heads: 8
- Kernel size: 15
- Output dimension: 256
This encoder handles the raw waveform, breaking it into 4-second attention blocks using self-conditioned CTC improving stability and accuracy during long audio sequences.
2. Speech Projector and Downsampler
To efficiently feed the LLM, the encoded audio features are compressed via a two-layer query transformer (Q-former). This step reduces the temporal resolution by a factor of 10 converting dense acoustic embeddings into compact semantically meaningful representations.
This speech-text modality adapter ensures that only the most relevant information reaches the language model optimizing memory and inference speed.
3. Granite-3.3-8B-Instruct Language Model
The transcribed or processed speech is passed to Granite-3.3-8B-Instruct, a general-purpose LLM with a 128K context length enabling long-form reasoning, summarization and translation. The same model can handle text-only prompts making Granite-Speech a unified multimodal system.
4. LoRA Adapters
To make fine-tuning efficient, Granite-Speech uses Low-Rank Adaptation (LoRA) with a rank of 64. These adapters are applied to the model’s query and value projection matrices allowing task-specific updates without retraining the entire network – a design that enables customization for industry-specific speech applications.
Training Data: Diversity Meets Scale
Granite-Speech-3.3-8B was trained on a combination of public and synthetic corpora ensuring both transparency and linguistic diversity. The training sources include well-known datasets such as:
- CommonVoice-17, MLS, LibriSpeech, VoxPopuli and AMI
- YODAS and Earnings-22 for domain-specific English
- Switchboard, CallHome and Fisher for conversational speech
In total, the dataset spans tens of thousands of hours of multilingual speech data. For speech translation (AST), IBM generated synthetic parallel datasets using Granite-3 and Phi-4 improving cross-lingual fluency.
Training took place on IBM’s Blue Vela supercomputing cluster, powered by NVIDIA H100 GPUs where 32 GPUs completed model training in 13 days – a testament to IBM’s optimized infrastructure.
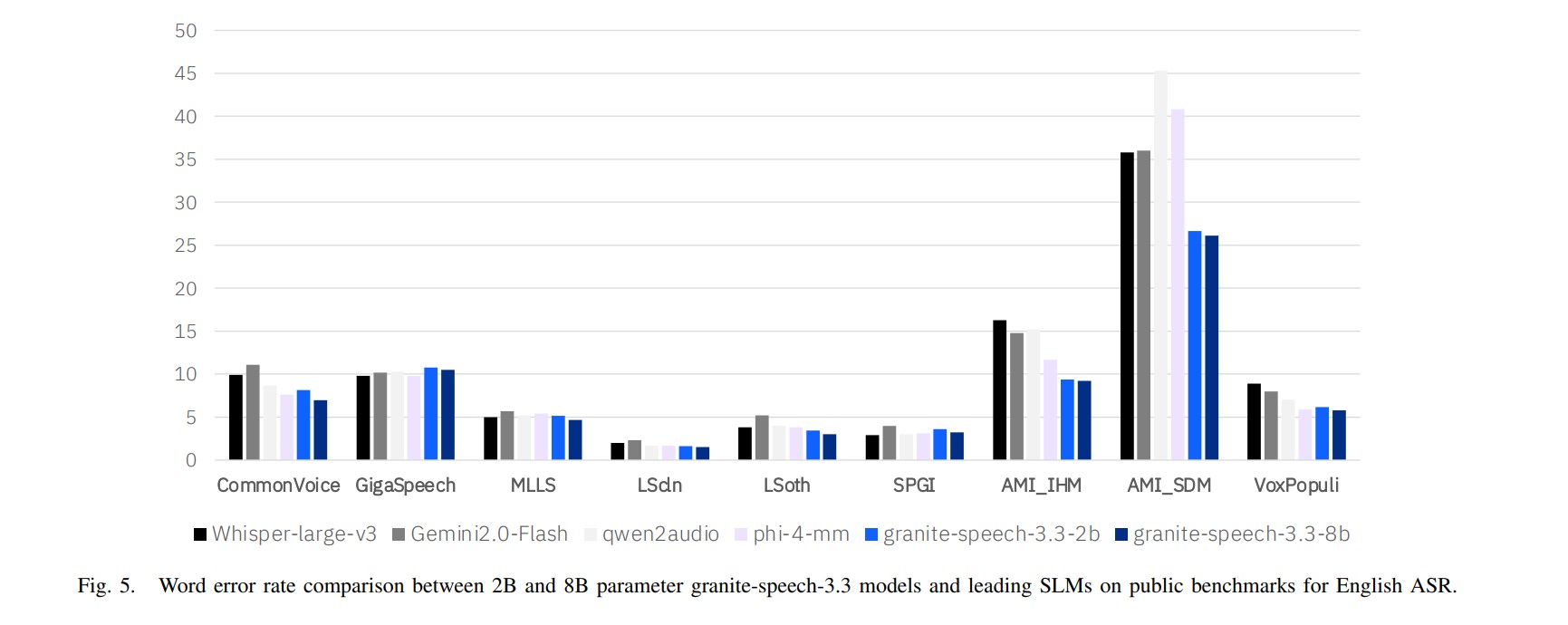
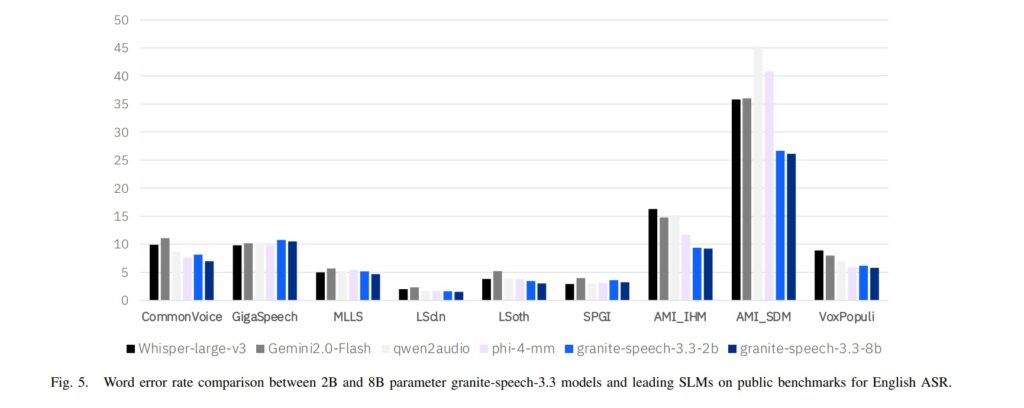
Performance and Evaluation
Granite-Speech-3.3-8B has been evaluated across a range of ASR and AST benchmarks with particular emphasis on English transcription accuracy.
Compared to earlier versions (3.3.0 and 3.3.1), the revision 3.3.2 demonstrates:
- Improved multilingual transcription (English, French, German, Spanish, Portuguese)
- Enhanced acoustic encoder depth for better fidelity
- Stronger cross-language alignment for English↔X translations
The model achieves competitive performance in the <8B parameter category outperforming many specialized ASR systems in both accuracy and robustness.
Ethical Considerations and Safety Design
IBM takes a cautious and enterprise-focused approach to AI deployment. The modular two-pass design of Granite-Speech inherently reduces risks by separating audio transcription from language interpretation.
If a malformed or adversarial audio input is provided, the model simply echoes its transcription rather than generating speculative or unsafe content.
Additionally, IBM encourages deploying Granite-Speech alongside Granite Guardian – a fine-tuned instruct model that flags potential risks such as bias, toxicity or hallucinations following the principles of the IBM AI Risk Atlas.
This careful layering of control, transparency, and ethical alignment makes Granite-Speech particularly suited for enterprise environments — healthcare, customer service, legal documentation and multilingual business communication.
Why Granite-Speech-3.3-8B Matters ?
In a landscape dominated by proprietary speech models, IBM’s open Apache-2.0-licensed release of Granite-Speech stands out. It brings:
- Open access and reproducibility
- Multilingual coverage across six major languages
- Safe modular architecture
- Fine-tuning flexibility for enterprise contexts
Its compatibility with Hugging Face Transformers and vLLM also ensures developers can easily integrate Granite-Speech into their pipelines whether for transcription, translation or multimodal AI applications.
Conclusion: A New Standard for Safe and Scalable Speech AI
With Granite-Speech-3.3-8B, IBM has built more than just another ASR model, it has engineered a scalable, multilingual and ethically grounded foundation for enterprise speech intelligence.
By aligning speech processing with the Granite LLM family, the model combines performance with transparency, enabling safer human-AI interaction across languages and industries.
As enterprises seek trustworthy AI systems that can understand, translate and act on spoken input, Granite-Speech-3.3-8B positions itself as a leading choice one that unites accuracy, adaptability and accountability in a single open model.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Thinking with Camera 2.0: A Powerful Multimodal Model for Camera-Centric Understanding and Generation
- Jio AI Classroom: Learn Artificial Intelligence for Free with Jio Institute & JioPC App
- Unsloth AI: The Game-Changer for Efficient 2*Faster LLM Fine-Tuning and Reinforcement Learning
- Ultimate OpenTSLM: Stanford’s Open-Source Framework Bridging LLMs and Medical Time-Series Data
- Quivr AI: Building Your Second Brain with Open-Source Generative Intelligence
References
- Granite-Speech-3.3-8B Model on Hugging Face
- Granite-3.3-8B-Instruct Language Model
- IBM Granite AI – Official Overview
- Granite Documentation & Tutorials
- Granite Learning Resources
- Granite Technical Report (arXiv:2505.08699)
- Granite Guardian: IBM’s AI Safety & Risk Detection Framework
4 thoughts on “Granite-Speech-3.3-8B: IBM’s Next-Gen Speech-Language Model for Enterprise AI”