India is one of the most linguistically diverse countries in the world, home to over 1,600 languages and dialects. Yet, speech technology for most of these languages has historically lagged behind due to limited data and resources. While English and a handful of global languages have benefited immensely from advancements in automatic speech recognition (ASR), Indian languages have remained underrepresented in major AI systems.
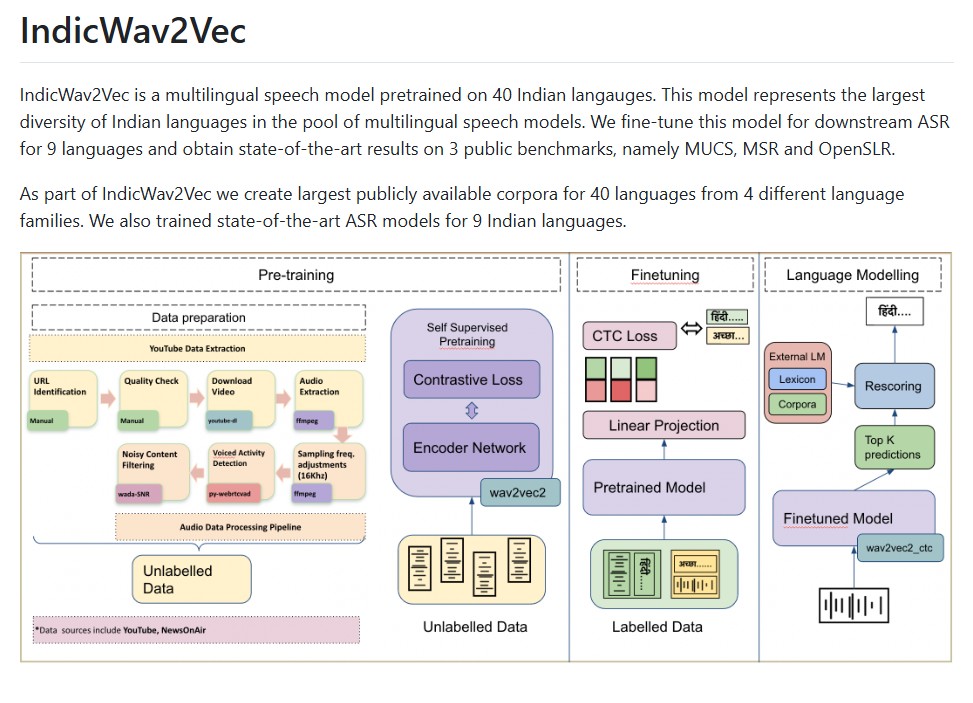
To address this gap, AI4Bharat, a research initiative at IIT Madras, developed IndicWav2Vec — a multilingual self-supervised speech model pre-trained on 40 Indian languages. IndicWav2Vec represents the largest linguistic diversity among multilingual speech models in India. It not only brings cutting-edge speech recognition to multiple regional languages but also enables developers and researchers to build inclusive voice-based technologies for millions of users across the subcontinent.
In this blog, we will explore how IndicWav2Vec is revolutionizing Indian language AI through self-supervised pretraining, fine-tuning for downstream ASR tasks, and open-source accessibility.
What Is IndicWav2Vec?
It is a large-scale, multilingual speech model trained on data from 40 Indian languages belonging to four major language families — Indo-Aryan, Dravidian, Tibeto-Burman and Austro-Asiatic.
Developed by AI4Bharat, the model builds upon Facebook’s Wav2Vec 2.0 architecture, adapting it for low-resource Indian languages through large-scale pretraining and fine-tuning. The result is a powerful model that supports Automatic Speech Recognition (ASR) for nine major Indian languages, achieving state-of-the-art accuracy on public benchmarks such as MUCS, MSR, and OpenSLR.
IndicWav2Vec is open-source under the MIT License, allowing developers, researchers and institutions to freely use and adapt it for their applications.
The Vision Behind IndicWav2Vec
AI4Bharat’s mission is to democratize language technology by building open, inclusive, and high-quality AI models for Indian languages. IndicWav2Vec is part of this larger ecosystem, which also includes tools for machine translation, text summarization, and language modeling.
By training a unified model across dozens of Indian languages, IndicWav2Vec aims to eliminate the linguistic digital divide. Its creation was supported by the EkStep Foundation, Bhashini Project (MeitY), Microsoft, and C-DAC’s Param Siddhi supercomputer, reflecting a strong collaboration between academia, industry and government.
Key Features of IndicWav2Vec
1. Multilingual Coverage at Scale
It supports 40 Indian languages, the highest coverage among open-source speech models. This includes widely spoken languages such as Hindi, Tamil, Telugu, Bengali, Marathi, Gujarati, Odia, Nepali and Sinhala along with several less-represented regional languages.
2. Self-Supervised Pretraining
The model is trained in a self-supervised manner, meaning it learns general speech representations from raw audio data without requiring manual transcripts. This allows it to efficiently adapt to low-resource languages with limited labeled data.
3. State-of-the-Art Performance
When fine-tuned for ASR tasks, IndicWav2Vec achieves benchmark-beating accuracy across major datasets. It performs exceptionally well on tasks involving spontaneous and conversational speech — a major challenge for regional Indian ASR systems.
4. Open-Source Accessibility
It is fully open-source and licensed under the MIT License. All pretrained and fine-tuned models are publicly available via Hugging Face and Fairseq allowing developers to integrate them seamlessly into their applications.
5. Easy Deployment via API and ULCA
AI4Bharat hosts IndicWav2Vec models on API endpoints and through ULCA (Universal Language Contribution API), allowing real-time speech-to-text inference for languages like Hindi, Tamil, Marathi and Telugu.
Technical Foundation
IndicWav2Vec is built using Fairseq, a popular PyTorch-based sequence modeling library developed by Meta AI. The model leverages Wav2Vec 2.0’s transformer-based architecture, adapted for multilingual data and fine-tuned for Indian languages.
Training Pipeline
- Data Collection:
The model was trained on a massive multilingual audio corpus collected from diverse open datasets, amounting to thousands of hours of unlabeled speech across 40 languages. - Preprocessing:
Steps such as voice activity detection (VAD), signal-to-noise ratio (SNR) filtering and chunking were applied to ensure high-quality input. - Pretraining:
The model was pretrained using masked predictive learning, where parts of the audio signal are masked and the model learns to predict them from the surrounding context. - Fine-Tuning for ASR:
IndicWav2Vec was fine-tuned on labeled ASR datasets for nine languages, achieving high performance on three major benchmarks: MUCS, MSR and OpenSLR.
Performance Benchmarks
IndicWav2Vec consistently outperforms previous models on multiple benchmarks. The following results show its performance (Word Error Rate – WER) across key Indian languages:
| Language | Model | WER (%) |
| Hindi | IndicWav2Vec + LM | 14.7 |
| Tamil | IndicWav2Vec + LM | 13.6 |
| Telugu | IndicWav2Vec + LM | 11.0 |
| Marathi | IndicWav2Vec + LM | 13.8 |
| Gujarati | IndicWav2Vec + LM | 11.7 |
| Odia | IndicWav2Vec + LM | 17.2 |
| Bengali | IndicWav2Vec + LM | 13.6 |
These results demonstrate substantial improvement over existing ASR systems, highlighting IndicWav2Vec’s robustness across multiple language families.
Quick Start for Developers
Developers can easily integrate IndicWav2Vec into their pipelines using Python.
Example: Greedy Decoding with Fairseq
python sfi.py –audio-file path/to/audio.wav –ft-model path/to/model.pt –w2l-decoder viterbi
Example: KenLM Decoding for Improved Accuracy
python sfi.py --audio-file path/to/audio.wav \ --ft-model path/to/model.pt \ --w2l-decoder kenlm \ --lexicon lexicon.lst \ --kenlm-model kenlm_model.arpa \ --beam 50 --lm-weight 2.0
Additionally, IndicWav2Vec can be accessed via Flask servers, TorchServe, or mobile deployment options.
Applications and Use Cases
It is already being used in a variety of real-world applications:
- Voice Assistants – Powering regional language interfaces for smart assistants and customer service bots.
- Educational Tools – Enabling accessible e-learning for rural and multilingual users.
- Government Platforms – Integrated into Bhashini, India’s national language AI platform, to promote inclusive governance.
- Media Transcription – Used for subtitling, content moderation and accessibility in news and entertainment industries.
- Healthcare & Accessibility – Supporting speech-based diagnostics and transcription tools for differently-abled users.
Collaboration and Acknowledgments
IndicWav2Vec was made possible through collaboration among AI4Bharat, IIT Madras, Microsoft, EkStep Foundation, C-DAC and MeitY’s Bhashini Project. Training was conducted on the Param Siddhi supercomputer, one of India’s fastest AI computing infrastructures.
This partnership exemplifies how open research, government initiatives and corporate support can accelerate innovation in public-interest AI.
Conclusion
IndicWav2Vec marks a major milestone in the journey toward AI inclusivity for Indian languages. By pretraining a massive multilingual model from scratch and fine-tuning it for state-of-the-art ASR, AI4Bharat has unlocked new possibilities for speech-based applications across India.
Its open-source release under the MIT License ensures that developers, educators, startups, and governments can freely use and adapt it to create voice technologies that truly reflect India’s linguistic diversity.
IndicWav2Vec is not just a model — it is a step toward bridging the digital language divide and empowering the next billion users through AI built for Bharat.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Distil-Whisper: Faster, Smaller, and Smarter Speech Recognition by Hugging Face
- Whisper by OpenAI: The Revolution in Multilingual Speech Recognition
- Omnilingual ASR: Meta’s Breakthrough in Multilingual Speech Recognition for 1600+ Languages
- LEANN: The Bright Future of Lightweight, Private, and Scalable Vector Databases
- Reducing Hallucinations in Vision-Language Models: A Step Forward with VisAlign
4 thoughts on “IndicWav2Vec: Building the Future of Speech Recognition for Indian Languages”