

Introduction to KNN
The K-Nearest Neighbors (KNN) algorithm is one of the most straightforward and effective algorithms in machine learning. It belongs to the supervised learning category, meaning it requires labeled data to learn from.
It’s commonly used for:
- Classification: Predicting discrete labels (e.g., spam or not spam)
- Regression: Predicting continuous values (e.g., house prices)
Despite its simplicity, KNN is surprisingly powerful and is often used as a baseline model when starting a machine learning problem.
The Core Idea Behind KNN
The core principle of KNN is:
“Similar things exist in close proximity.”
In simple words, when a new data point needs a prediction, KNN checks how its nearby “neighbors” in the training set behaved and uses that information to decide the new output.
For example, if you live in a neighborhood where most people drive SUVs, chances are that you also drive an SUV. That’s the essence of KNN.
Step-by-Step Working of the KNN Algorithm
Let’s break it down into steps:
1. Choose a value for K
- This is the number of nearest neighbors to consult when making a prediction.
- Example: If K = 3, the model will consider the 3 nearest points to classify the input.
2. Calculate the distance
- The “nearness” is usually measured using Euclidean distance, though other distance metrics like Manhattan or Minkowski can also be used.

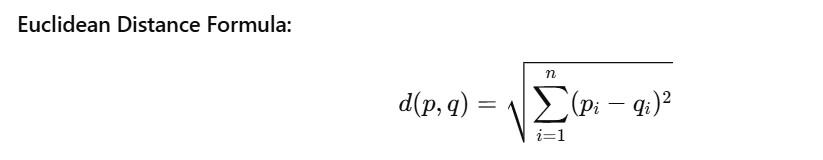
Where:
- p and q are two points in n-dimensional space.
3. Find the K nearest neighbors
- After calculating distances, we sort the training data points by how close they are to the new point.
- We pick the top K closest points.
4. Make predictions
- For classification:
- The new point gets assigned the most frequent class among the K neighbors.
- For regression:
- The prediction is the average value of the K neighbors.
Choosing the Right Distance Metric
Choosing the right distance metric is important:
Manhattan Distance (better for high-dimensional data):

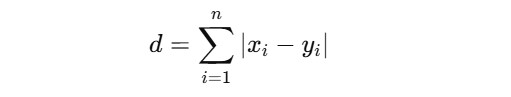
Euclidean Distance (default for continuous variables):

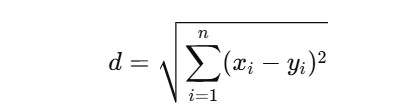
Note: Always scale your features before using KNN to avoid bias from larger-valued features.
How to Choose the Best K?
Choosing the right K is crucial for model performance:
- If K is too small (like 1), the model can be too sensitive to noise — this leads to overfitting.
- If K is too large, the model may become too generalized — this leads to underfitting.
A common technique is to test multiple K values using cross-validation and pick the one with the best performance.
Pros of KNN
✅ Simple to understand and implement
✅ No training phase — great for real-time predictions
✅ Works well with small datasets
✅ Versatile — can be used for both classification and regression
Cons of KNN
❌ Slow prediction for large datasets (lazy learning algorithm)
❌ Requires all data to be stored (memory-heavy)
❌ Sensitive to feature scaling and irrelevant features
❌ Suffers in high-dimensional spaces (curse of dimensionality)
Conceptual Example: Classifying Fruits
Imagine you have data about fruits based on weight and color:
| Weight (g) | Color Score | Fruit |
|---|---|---|
| 150 | 0.8 | Apple |
| 180 | 0.9 | Apple |
| 120 | 0.2 | Orange |
| 130 | 0.3 | Orange |
Now, a new fruit has:
- Weight = 160g
- Color score = 0.85
You apply KNN with K=3:
- Find distances to all points
- Pick the 3 closest ones (likely two Apples, one Orange)
- Majority is Apple → Classify the new fruit as Apple
KNN Is a Lazy Learner – What Does That Mean?
KNN is called a lazy learner because it doesn’t actually learn a model during training. Instead, it stores the entire training dataset and makes decisions only at the time of prediction.
This makes training fast, but prediction slow, especially for large datasets.
When Should You Use KNN?
Use KNN when:
- The dataset is small
- Feature space is low-dimensional
- You want a quick baseline model
- Data is well-labeled and not noisy
Avoid KNN when:
- You’re working with large-scale or high-dimensional data
- Real-time predictions are required
- Data is imbalanced or poorly scaled
Key Takeaways
| Topic | Summary |
|---|---|
| Type of Algorithm | Supervised Learning |
| Used For | Classification & Regression |
| Core Idea | Predict based on the majority or average of nearest neighbors |
| Requires Training? | No – it’s a lazy learner |
| Common Distance Metric | Euclidean distance |
| Important Hyperparameter | K (number of neighbors) |
| Preprocessing Required? | Yes – especially feature scaling |