The rapid evolution of large language models (LLMs) has unlocked new capabilities in natural language understanding, reasoning, coding and multimodal tasks. However, as models grow more advanced, one major challenge persists: computational efficiency. Traditional full-attention architectures struggle to scale efficiently, especially when handling long context windows and real-time inference workloads. The increasing demand for agent-like behavior, tool usage and reinforcement-learning-driven reasoning only intensifies this challenge.
Enter Kimi Linear, a breakthrough hybrid linear attention architecture designed to deliver superior performance with significantly higher efficiency. Developed by the Kimi team, this architecture introduces a novel module called Kimi Delta Attention (KDA) offering exceptional improvements in speed, memory usage and long-context reasoning abilities. In this blog, we will explore what Kimi Linear is, how it works and why it matters for the future of AI.
What Is Kimi Linear?
Kimi Linear is a next-generation attention mechanism combining the strength of traditional multi-head attention and innovative linear attention. It provides a hybrid structure where three KDA layers are interleaved with one standard Multi-Head Latent Attention (MLA) layer, striking an optimal balance between speed and accuracy.
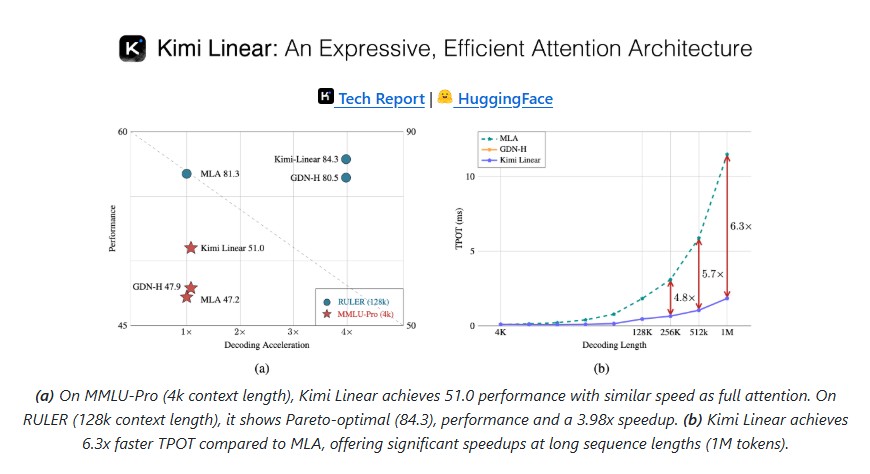
Unlike pure full-attention models where memory and computation grow significantly with sequence length, Kimi Linear reduces key-value (KV) cache usage by nearly 75 percent and improves decoding throughput by up to 6× on million-token context benchmarks. In practical terms, this means faster inference, lower hardware cost and better scalability without compromising accuracy.
The Innovation Behind Kimi Delta Attention (KDA)
At the core of Kimi Linear lies KDA, an enhanced linear attention mechanism inspired by Gated DeltaNet. KDA improves the finite-memory architecture used in linear attention by introducing channel-wise gating, allowing each feature dimension to forget or retain information independently. This fine-grained control helps the model balance stability, memory retention and expressiveness effectively.
Key innovations include:
1. Fine-Grained Gating
Instead of using a single decay value per head (as in previous models), KDA applies decay at the channel level. This enables more precise control of information flow and enhances the model’s ability to capture long-range dependencies.
2. Efficient State Update
KDA uses a diagonal-plus-low-rank (DPLR) transition mechanism but optimizes it to remove redundant matrix multiplications. This results in faster training and inference without sacrificing performance.
3. Hybrid Attention Strategy
A 3:1 ratio of KDA to MLA layers ensures that global information flow is maintained while achieving massive efficiency gains in memory and compute.
Why This Matters
These innovations allow Kimi Linear to outperform softmax-based full attention models across short-context and long-context benchmarks while also enabling extreme scalability up to 1 million tokens.
Performance and Benchmark Results
Kimi Linear has demonstrated strong performance across a wide range of benchmarks, including:
- Short-context tasks: Outperforms full-attention MLA models on MMLU, BBH, ARC and TriviaQA.
- Long-context evaluations: Tops benchmarks like RULER and RepoQA, proving robust long-context capabilities.
- Coding & Math reasoning: Shows superior performance on complex reasoning and competitive programming tasks.
- Reinforcement learning settings: Exhibits faster and more stable convergence during RL-driven reasoning tasks.
These results highlight Kimi Linear’s versatility across both pretraining and post-training stages.
Efficiency Advantages
Efficiency is where Kimi Linear truly shines.
Key Efficiency Wins
- KV cache reduction: Up to 75 percent less memory usage.
- Decoding speed: Up to 6× faster at 1M context length.
- Prefill speed: 2.9× faster than full attention at extreme sequence lengths.
- Compute efficiency: Better scaling law performance than full MLA models.
In real-world terms, this means models can handle longer tasks, power more interactive applications and deploy more cost-effectively across cloud and on-device environments.
Why Kimi Linear Matters for the Future of AI
Enables Longer Reasoning Sessions
With context support up to one million tokens, Kimi Linear paves the way for persistent, memory-augmented AI assistants capable of complex reasoning across long task sequences.
Supports Agent-Style AI
Modern AI applications require decision-making, planning and tool execution. Kimi Linear’s efficient memory usage and fast inference align perfectly with agent-driven workloads.
Lowers Deployment Costs
High performance without massive GPU demands democratizes LLM deployment and makes advanced AI accessible to more organizations and users.
Hybrid is the New Standard
Just as hybrid engines changed transportation, hybrid attention models like Kimi Linear may soon become the default architecture for advanced large-scale AI systems.
Conclusion
Kimi Linear presents a transformative leap in attention mechanisms for large language models. By combining the best of linear attention and full attention, it achieves remarkable gains in performance, efficiency and scalability. With breakthroughs in fine-grained gating, long-context handling and hardware-optimized design, Kimi Linear sets a new benchmark for AI architectures moving forward.
As the demand for intelligent, interactive, and long-context AI grows, architectures that deliver both power and efficiency will shape the future. Kimi Linear stands firmly at this frontier proving that smarter models do not always need bigger compute.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- FIBO: The First JSON-Native, Open-Source Text-to-Image Model Built for Real-World Control and Accuracy
- olmOCR: Redefining Document Understanding with Vision-Language Models
- DeepSeek-V3: Pioneering Large-Scale AI Efficiency and Open Innovation
- Krea Realtime 14B: Redefining Real-Time Video Generation with AI
- LongCat-Video: Meituan’s Groundbreaking Step Toward Efficient Long Video Generation with AI
2 thoughts on “Kimi Linear: The Future of Efficient Attention in Large Language Models”