In the world of digital transformation, the ability to accurately extract and interpret information from complex documents is becoming increasingly essential. Whether for academic research, financial analysis or enterprise automation, document parsing – the process of converting structured and unstructured document data into machine-readable formats plays a vital role.
Enter MinerU2.5, a groundbreaking vision-language model (VLM) developed by the Shanghai Artificial Intelligence Laboratory in collaboration with leading academic institutions. MinerU2.5 offers a revolutionary two-stage, decoupled approach to document parsing that delivers state-of-the-art (SOTA) accuracy and unmatched computational efficiency.
This article explores how MinerU2.5 changes the game in high-resolution document understanding, highlighting its architecture, unique features and impact on real-world applications.
What is MinerU2.5?
It is a 1.2-billion-parameter AI model designed to read, interpret and understand high-resolution documents with precision. Unlike conventional end-to-end OCR or vision-language models that process entire documents at once, MinerU2.5 introduces a decoupled, coarse-to-fine parsing strategy.
This approach separates global layout analysis (understanding structure and organization) from local content recognition (reading the actual text, tables and formulas). The result is a system that can handle complex, dense and multi-layout documents, all while maintaining high speed and accuracy.
The Two-Stage Parsing Strategy: A Breakthrough in Efficiency
One of MinerU2.5’s most impressive innovations is its two-stage parsing pipeline designed to overcome the efficiency and scalability challenges of traditional models.
Stage 1: Global Layout Analysis
At this stage, MinerU2.5 processes a downsampled version of the document to quickly identify its structural layout including headers, tables, text blocks, formulas and figures. This allows the model to gain a holistic understanding of the document’s composition while minimizing computational cost.
Stage 2: Fine-Grained Content Recognition
Once the layout is mapped, MinerU2.5 zooms into specific areas of the original high-resolution document for detailed recognition. This step involves parsing native-resolution crops ensuring the system preserves intricate details like mathematical formulas, tables and multilingual text.
This coarse-to-fine design not only improves recognition accuracy but also reduces token redundancy – a common issue in vision-language models that process large blank or low-information regions. MinerU2.5 thus achieves higher efficiency with significantly fewer resources compared to its predecessors and competitors.
Key Innovations That Power MinerU2.5
1. Decoupled Architecture
MinerU2.5’s architecture integrates three key components:
- NativeRes-ViT Vision Encoder – Handles images at varying resolutions and aspect ratios with 2D positional encoding.
- Patch Merger – Compresses and optimizes visual information before it reaches the language model.
- Qwen2-Instruct Language Decoder – A lightweight 0.5B-parameter language model that interprets and generates structured textual outputs.
This modular design ensures flexibility, interpretability and computational balance – all critical for large-scale deployment.
2. Closed-Loop Data Engine
The MinerU2.5 team developed a Data Engine that systematically collects, refines and annotates massive datasets. It employs Iterative Mining via Inference Consistency (IMIC), a novel technique that identifies “hard cases” where the model struggles enabling targeted retraining and continuous improvement.
This ensures that MinerU2.5 learns from diverse, high-quality data covering layouts, languages and document types such as research papers, reports and financial documents.
3. Advanced Layout and Formula Recognition
MinerU2.5 redefines layout analysis with a unified tagging system that covers everything from headers and footers to code blocks and page numbers. It also introduces PageIoU, a new metric that more accurately measures layout consistency.
For formula recognition, the model uses an Atomic Decomposition & Recombination (ADR) framework which breaks down complex multi-line equations into smaller components for precise parsing – a major leap in handling mathematical and scientific documents.
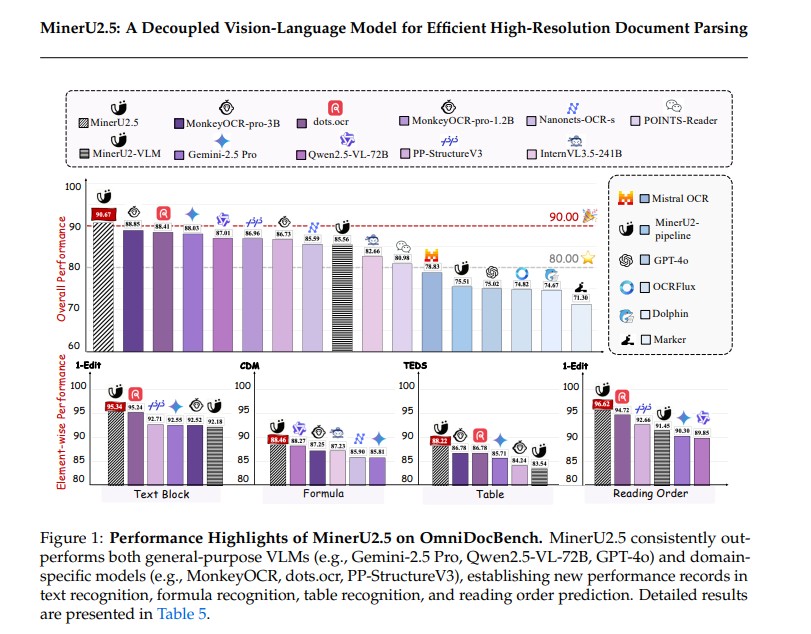
Performance: Setting New Industry Standards
On the OmniDocBench benchmark – one of the most comprehensive tests for document parsing models -MinerU2.5 achieved record-breaking performance:
| Model | Overall Score | Text Accuracy | Formula Accuracy | Table Accuracy |
|---|---|---|---|---|
| GPT-4o | 75.02 | 79.70 | 67.07 | 76.09 |
| dots.ocr | 88.41 | 83.22 | 86.78 | 90.62 |
| MinerU2.5 | 90.67 | 88.46 | 88.22 | 92.38 |
These results show that MinerU2.5 not only outperforms general-purpose models like GPT-4o and Gemini-2.5 Pro but also surpasses domain-specific solutions such as MonkeyOCR and dots.ocr.
Moreover, its efficiency benchmarks demonstrate remarkable throughput achieving up to 4.47 pages per second on NVIDIA H200 GPUs with over 4,900 tokens per second all while maintaining state-of-the-art accuracy.
Real-World Applications of MinerU2.5
MinerU2.5’s versatility makes it ideal for a wide range of industries and research fields:
- Academic Publishing: Automates extraction of citations, equations and references from scholarly papers.
- Finance & Law: Parses contracts, invoices and financial reports with structural precision.
- Enterprise Automation: Powers intelligent document processing (IDP) systems for scalable data workflows.
- AI Knowledge Systems: Enhances Retrieval-Augmented Generation (RAG) pipelines by providing accurate structured inputs.
Its multilingual and multimodal capabilities also make it suitable for global applications where content may mix languages, scripts and mathematical notations.
Conclusion
MinerU2.5 is more than just an upgrade , it represents a paradigm shift in AI-driven document understanding. By decoupling layout analysis from content recognition employing a robust data engine and introducing innovative metrics and architectures, MinerU2.5 achieves the perfect balance between accuracy, interpretability and efficiency.
For developers, researchers, and enterprises seeking to unlock the true potential of high-resolution document parsing, MinerU2.5 sets a new gold standard. It’s not just faster – it’s smarter, leaner and more capable of transforming how we interact with digital documents.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Diffusion Transformers with Representation Autoencoders (RAE): The Next Leap in Generative AI
- LLaMAX2 by Nanjing University, HKU, CMU & Shanghai AI Lab: A Breakthrough in Translation-Enhanced Reasoning Models
- Granite-Speech-3.3-8B: IBM’s Next-Gen Speech-Language Model for Enterprise AI
- Thinking with Camera 2.0: A Powerful Multimodal Model for Camera-Centric Understanding and Generation
- Jio AI Classroom: Learn Artificial Intelligence for Free with Jio Institute & JioPC App
References
- GitHub Repository (Source Code):
https://github.com/opendatalab/MinerU - Hugging Face Model Page:
https://huggingface.co/opendatalab/MinerU2.5-2509-1.2B - ArXiv Paper (Official Publication):
https://arxiv.org/abs/2509.22186v2 - LLaVA-Pretrain Dataset:
https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain - LLaVA-Instruct-150K Dataset:
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/tree/main - Dingo QA Tool (used for annotation quality assurance):
https://github.com/MigoXLab/dingo
3 thoughts on “MinerU2.5 by Shanghai AI Lab, Peking University & Shanghai Jiao Tong University Sets New Standard for AI-Powered Document Parsing”