
The field of artificial intelligence is rapidly transitioning from single-turn text generation systems to autonomous, agentic models capable of reasoning, planning, coding and executing long-horizon tasks. As demand grows for AI systems that can reliably handle complex workflows, multilingual software development and tool-driven automation, open-source solutions with competitive performance are becoming increasingly valuable.
MiniMax-M2.1, released by MiniMaxAI, represents a major milestone in this evolution. Rather than being a routine parameter upgrade, MiniMax-M2.1 is a purpose-built agentic language model designed to rival top closed-source systems while remaining fully transparent and accessible to the developer community. With strong results across software engineering, tool use and long-horizon planning benchmarks, MiniMax-M2.1 aims to democratize high-end AI agent capabilities.
This article provides a detailed overview of MiniMax-M2.1, covering its vision, benchmarks, agentic strengths, deployment options and real-world applications.
What Is MiniMax-M2.1?
MiniMax-M2.1 is a large-scale text generation and agentic language model released as open-source under a Modified MIT license. It is optimized for:
- Coding and software engineering
- Tool calling and automation
- Instruction following
- Multilingual reasoning
- Long-horizon planning and execution
Unlike many research-only releases, MiniMax-M2.1 is designed to be production-ready, supporting local deployment, API usage and integration with popular inference frameworks such as vLLM, SGLang and Transformers.
MiniMaxAI positions M2.1 as a foundation for the next generation of autonomous applications, including AI coding agents, office automation systems and full-stack development assistants.
Core Design Philosophy
MiniMax-M2.1 was developed to challenge the assumption that state-of-the-art agentic performance must remain proprietary. The model emphasizes:
- Robustness over narrow optimization, ensuring stable performance across diverse frameworks
- Generalization, allowing it to work effectively with different agent scaffolds
- Transparency and control, enabling developers to understand, modify and deploy the model freely
This philosophy makes MiniMax-M2.1 particularly appealing to enterprises and researchers seeking vendor-independent AI solutions.
Benchmark Performance Overview
MiniMax-M2.1 delivers substantial improvements over its predecessor, MiniMax-M2 and competes closely with leading closed-source models such as Claude Sonnet 4.5 and Claude Opus 4.5.
Software Engineering and Coding Benchmarks
MiniMax-M2.1 excels on industry-standard software engineering benchmarks:
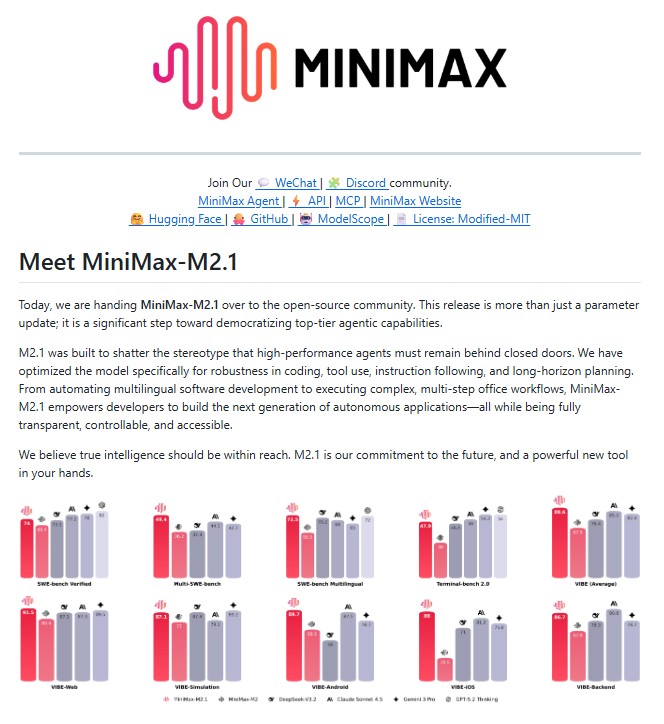
- SWE-bench Verified: 74.0
- Multi-SWE-bench: 49.4
- SWE-bench Multilingual: 72.5
- Terminal-bench 2.0: 47.9
These results highlight strong capabilities in debugging, patch generation and real-world codebase reasoning. Notably, its multilingual SWE-bench performance demonstrates superior handling of non-English programming environments, a key advantage for global development teams.
Agent Framework Generalization
A major strength of MiniMax-M2.1 is its framework-agnostic stability. When evaluated across multiple coding agent frameworks such as Claude Code, Droid and mini-swe-agent, the model maintains consistent performance without heavy prompt engineering or task-specific tuning.
This robustness is critical for real-world deployment where AI agents must adapt to varying toolchains, system prompts and execution environments.
Advanced Code Intelligence
Beyond standard coding benchmarks, MiniMax-M2.1 shows strong results in specialized software engineering tasks:
- Test case generation
- Code performance optimization
- Code review and defect detection
- Instruction-constrained development
On internal benchmarks such as SWE-Review, SWE-Perf and OctoCodingbench, the model consistently outperforms MiniMax-M2 and often matches or exceeds Claude Sonnet 4.5. This makes it suitable for professional development workflows, CI/CD automation, and large-scale refactoring tasks.
VIBE: Full-Stack Application Development
To evaluate real-world, end-to-end development capabilities, MiniMaxAI introduced VIBE (Visual & Interactive Benchmark for Execution). Unlike traditional benchmarks, VIBE assesses whether a model can generate fully functional applications with correct logic, runtime behavior and visual output.
MiniMax-M2.1 achieves an impressive 88.6 average score across VIBE, with standout results in:
- VIBE-Web: 91.5
- VIBE-Android: 89.7
- VIBE-iOS: 88.0
These scores confirm MiniMax-M2.1’s ability to architect applications “from zero to one,” covering frontend, backend and platform-specific logic.
Tool Use and Long-Horizon Reasoning
MiniMax-M2.1 demonstrates steady improvements in tool-based reasoning and long-context task management, as seen in benchmarks such as:
- Toolathlon: 43.5
- BrowseComp: 47.4
- BrowseComp (context management): 62.0
These results indicate strong performance in web navigation, context pruning and multi-step information gathering, essential traits for autonomous research agents and enterprise automation bots.
Multilingual and General Intelligence
In addition to coding and tools, MiniMax-M2.1 performs competitively on general intelligence and reasoning benchmarks:
- AIME25: 83.0
- MMLU-Pro: 88.0
- GPQA-Diamond: 83.0
- IFBench: 70.0
This balanced intelligence profile ensures the model is not limited to software tasks alone making it useful for knowledge work, analytics and decision-support systems.
Deployment and Ecosystem Support
MiniMax-M2.1 is designed for flexible deployment across environments:
- Local deployment: Via Hugging Face model weights
- Inference frameworks: SGLang, vLLM, Transformers, KTransformers
- API access: MiniMax Open Platform
- Agent product: MiniMax Agent (publicly available)
Recommended inference parameters include temperature=1.0, top_p=0.95 and top_k=40, ensuring optimal balance between creativity and reliability.
The model supports FP8, BF16 and FP32, enabling efficient inference on modern GPU hardware.
Real-World Use Cases
MiniMax-M2.1 is well-suited for a wide range of applications, including:
- Autonomous coding agents and DevOps automation
- Multilingual software development teams
- Enterprise workflow orchestration
- AI-powered code review and quality assurance
- Full-stack application prototyping
- Research on long-horizon AI agents
Its open-source nature makes it particularly attractive for organizations seeking long-term control and customization.
Conclusion
MiniMax-M2.1 marks a significant step forward in open-source agentic AI. By delivering strong performance across software engineering, tool use and full-stack development benchmarks, it proves that high-end autonomous capabilities no longer need to be locked behind proprietary APIs.
With robust framework generalization, competitive benchmark results, and flexible deployment options, MiniMax-M2.1 empowers developers and enterprises to build sophisticated AI agents with transparency and confidence. As the ecosystem continues to mature, MiniMax-M2.1 is poised to become a foundational model for the next generation of autonomous applications.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Orion: The Next Evolution in Visual AI for Advanced Reasoning and Multi-Modal Intelligence
- Fara-7B: Microsoft’s Breakthrough Agentic Model for Real-World Computer Use
- MiniMax-M2.1: An Open-Source Leap Toward Enterprise-Grade Agentic AI
- Supabase: The Complete Guide to the Open-Source Postgres Development Platform
- K-EXAONE-236B-A23B: A Deep Dive into LG AI Research’s Frontier Multilingual Reasoning Model
11 thoughts on “MiniMax-M2.1: An Open-Source Leap Toward Enterprise-Grade Agentic AI”