The rise of large language models (LLMs) has redefined artificial intelligence powering everything from conversational AI to autonomous reasoning systems. However, training these models especially through reinforcement learning (RL) is computationally expensive requiring massive GPU resources and long training cycles.
To address this, a team of researchers from NVIDIA, Massachusetts Institute of Technology (MIT), The University of Hong Kong (HKU) and Tsinghua University (THU) unveiled QeRL — Quantization-Enhanced Reinforcement Learning, a cutting-edge framework that revolutionizes the way LLMs learn, reason and optimize themselves.
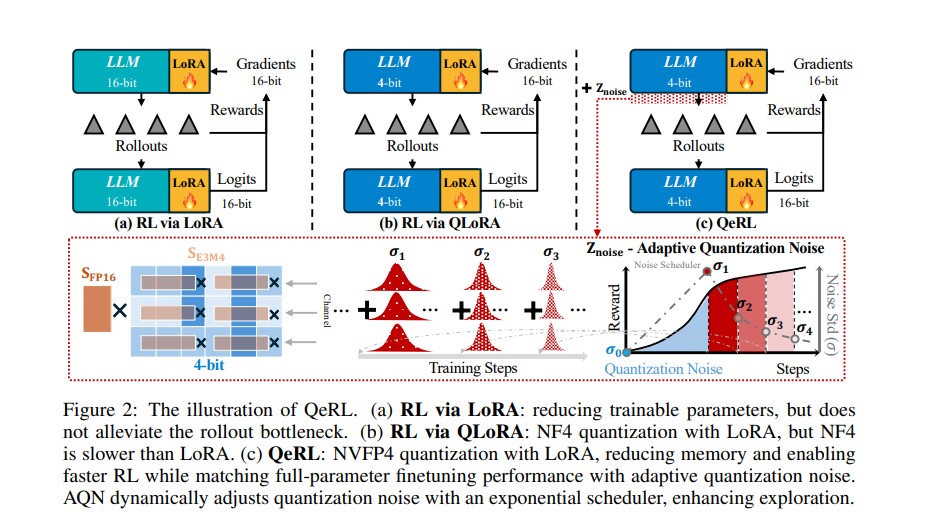
QeRL introduces a remarkable fusion of NVFP4 quantization and Low-Rank Adaptation (LoRA) enabling faster, more efficient and smarter reinforcement learning for large models – all without sacrificing accuracy.
What is QeRL?
QeRL, short for Quantization-Enhanced Reinforcement Learning is designed to make RL-based fine-tuning of large language models both resource-efficient and performance-driven.
Traditionally, reinforcement learning helps LLMs learn through feedback signals refining reasoning and problem-solving abilities. However, this process is slow and resource-hungry as it requires multiple models to run simultaneously (like policy and reference models) and generates long rollouts during training.
QeRL solves these bottlenecks by introducing quantization-aware training reducing memory requirements while enhancing exploration – a key aspect of reinforcement learning.
In simpler terms, QeRL makes large models smarter, faster and cheaper to train.
The Core Innovation: Quantization Meets Reinforcement Learning
At the heart of QeRL lies the fusion of two concepts – quantization and Low-Rank Adaptation (LoRA) both optimized for next-generation GPU architectures like NVIDIA Hopper and Blackwell.
1. NVFP4 Quantization: Smarter Precision Control
QeRL adopts NVFP4 (NVIDIA FP4) quantization – a high-performance 4-bit floating-point format supported natively by NVIDIA GPUs. This drastically reduces memory consumption while maintaining high numerical accuracy. Compared to older 4-bit formats like NF4, NVFP4 provides finer-grained scaling and faster rollout speeds.
2. Low-Rank Adaptation (LoRA): Parameter Efficiency
LoRA limits the number of trainable parameters by learning only low-dimensional updates keeping the majority of model weights frozen. This makes fine-tuning efficient even for 32-billion-parameter models.
By combining these two techniques, QeRL reduces the computational burden of RL training by up to 1.5× while achieving accuracy comparable to full-parameter fine-tuning – a groundbreaking feature in AI optimization.
Adaptive Quantization Noise: A Novel Exploration Mechanism
One of the most fascinating discoveries in QeRL is that quantization noise traditionally seen as harmful actually enhances exploration in reinforcement learning.
When a model is quantized, slight random variations (noise) are introduced into its weights. The QeRL team found that this noise increases policy entropy meaning the model becomes less deterministic and more willing to explore alternative reasoning paths.
This “controlled randomness” leads to faster learning as the model avoids overfitting to early solutions and instead searches for more optimal strategies similar to how humans learn through trial and error.
To make this effect even more powerful, it introduces Adaptive Quantization Noise (AQN) – a dynamic mechanism that adjusts the noise level over time using an exponential decay scheduler. Early in training, higher noise boosts exploration; later the noise reduces to allow stable convergence.
This innovation not only stabilizes training but also helps QeRL outperform conventional RL methods in both speed and accuracy.
Performance Benchmarks: Efficiency Without Compromise
The research team rigorously tested QeRL on the Qwen2.5 family of models across popular mathematical reasoning datasets, including GSM8K, MATH 500, AIME 2025 and AMC 23.
Key Highlights:
- 1.5× faster rollout and end-to-end training compared to 16-bit LoRA.
- Memory usage reduced by 50–60%, enabling training of 32B models on a single NVIDIA H100 GPU.
- Accuracy surpassing LoRA and QLoRA and matching full-parameter fine-tuning on major reasoning benchmarks.
- GSM8K accuracy: 90.8% with QeRL (vs. 88.1% for 16-bit LoRA).
- MATH 500 accuracy: 77.4% for QeRL matching full-precision performance.
In essence, QeRL delivers both speed and precision redefining what’s possible in RL-based training for LLMs.
Why QeRL Matters ?
1. Enables Scalable RL Training
Before QeRL, training a 32B-parameter model using reinforcement learning required multiple GPUs and massive memory resources. It makes it possible to do so on a single H100 GPU democratizing access to RL-based LLM training.
2. Beyond Efficiency — Smarter Learning
Unlike conventional efficiency-focused methods, it goes “beyond efficiency.” By leveraging quantization noise for exploration, it improves reasoning depth helping models find better solutions in tasks like mathematical problem solving and code generation.
3. Compatibility with Modern Architectures
It is optimized for NVIDIA’s NVFP4 kernel and integrates seamlessly with Marlin, a mixed-precision inference framework. This ensures maximum hardware utilization without compromising accuracy.
The Institutions Behind QeRL
QeRL represents a global collaboration between leading AI research institutions:
- NVIDIA — For GPU optimization and NVFP4 quantization technology.
- Massachusetts Institute of Technology (MIT) — For reinforcement learning algorithmic innovation.
- The University of Hong Kong (HKU) — For applied AI research and evaluation.
- Tsinghua University (THU) — For mathematical reasoning and model optimization.
Together, these institutions are shaping the future of AI model efficiency and reasoning intelligence.
Conclusion
QeRL is more than an optimization technique – it’s a paradigm shift in how large language models learn, explore and evolve. By combining the power of quantization, parameter efficiency and adaptive exploration, QeRL achieves what was once thought impossible: faster, smarter and leaner reinforcement learning for large models.
As the AI industry continues to push toward ever-larger models, frameworks like QeRL are key to making progress sustainable, scalable and accessible.
With its open-source release, it is poised to become the cornerstone for next-generation AI training and fine-tuning where efficiency meets intelligence.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- MinerU2.5 by Shanghai AI Lab, Peking University & Shanghai Jiao Tong University Sets New Standard for AI-Powered Document Parsing
- Diffusion Transformers with Representation Autoencoders (RAE): The Next Leap in Generative AI
- LLaMAX2 by Nanjing University, HKU, CMU & Shanghai AI Lab: A Breakthrough in Translation-Enhanced Reasoning Models
- Granite-Speech-3.3-8B: IBM’s Next-Gen Speech-Language Model for Enterprise AI
- Thinking with Camera 2.0: A Powerful Multimodal Model for Camera-Centric Understanding and Generation
References
GitHub: https://github.com/NVlabs/QeRL
ArXiv Paper: https://arxiv.org/abs/2510.11696v1
3 thoughts on “NVIDIA, MIT, HKU and Tsinghua University Introduce QeRL: A Powerful Quantum Leap in Reinforcement Learning for LLMs”