
The rapid evolution of large language models (LLMs) has reshaped artificial intelligence, enabling machines to understand, reason, and generate human-like language at unprecedented levels. However, this progress has come with significant challenges, particularly in terms of computational cost, inference speed, and scalability for long-context applications. Addressing these challenges, the Qwen team has introduced Qwen3-Next-80B-A3B-Instruct, a next-generation open-source language model designed to deliver high performance with remarkable efficiency.
Qwen3-Next-80B-A3B-Instruct represents a major architectural shift in how large models are built and deployed. With an innovative hybrid attention mechanism, high-sparsity Mixture-of-Experts (MoE) design, and native support for ultra-long context lengths, this model sets a new benchmark for efficient and scalable AI systems.
What Is Qwen3-Next-80B-A3B-Instruct?
Qwen3-Next-80B-A3B-Instruct is an instruction-tuned causal language model developed by the Qwen team under the Apache 2.0 open-source license. While the model has 80 billion total parameters, only 3 billion parameters are activated per token, making it dramatically more efficient than traditional dense models of similar size.
This model is part of the Qwen3-Next series, which focuses on improving scaling efficiency without compromising reasoning, creativity, or long-context understanding. It is specifically optimized for instruction-following tasks and does not generate hidden reasoning blocks, ensuring clean and direct outputs suitable for production environments.
Key Architectural Innovations
Hybrid Attention Mechanism
One of the most significant advancements in Qwen3-Next-80B-A3B-Instruct is its Hybrid Attention architecture. Instead of relying solely on traditional self-attention, the model combines:
- Gated DeltaNet for efficient linear attention
- Gated Attention for high-quality contextual reasoning
This hybrid approach allows the model to process extremely long sequences while maintaining stability and speed, making it ideal for tasks involving massive documents, logs, or multi-turn conversations.
High-Sparsity Mixture-of-Experts (MoE)
The model employs an advanced Mixture-of-Experts architecture with:
- 512 total experts
- Only 10 experts activated per token
- 1 shared expert for stability
This design drastically reduces floating-point operations (FLOPs) while preserving the expressive power of an 80B-parameter model. As a result, Qwen3-Next-80B-A3B-Instruct achieves performance comparable to much larger models at a fraction of the computational cost.
Multi-Token Prediction (MTP)
Multi-Token Prediction is another innovation that boosts both training efficiency and inference speed. Instead of predicting one token at a time, the model can predict multiple future tokens in a single step, significantly increasing throughput when supported by optimized inference frameworks such as vLLM and SGLang.
Ultra-Long Context Capabilities
Qwen3-Next-80B-A3B-Instruct natively supports 262,144 tokens of context length, far exceeding the standard limits of most LLMs. With YaRN-based RoPE scaling, the model has been validated to handle up to 1 million tokens, making it suitable for:
- Legal and financial document analysis
- Research paper summarization
- Codebase-level reasoning
- Enterprise knowledge retrieval systems
This long-context performance places Qwen3-Next among the strongest open-source models available for large-scale document understanding.
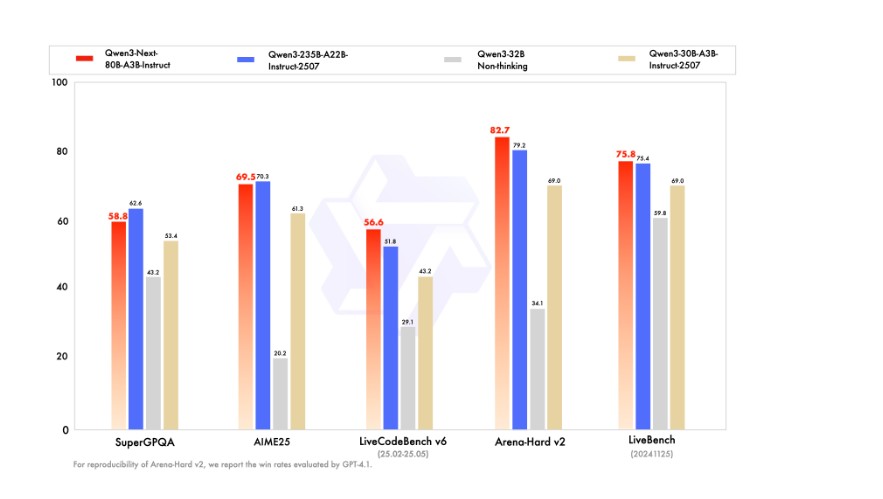
Benchmark Performance
Despite its efficiency-focused design, Qwen3-Next-80B-A3B-Instruct delivers impressive benchmark results:
- Knowledge Tasks: Strong performance on MMLU-Pro and GPQA benchmarks
- Reasoning: Competitive scores on AIME and complex math reasoning tasks
- Coding: Outperforms many dense models on LiveCodeBench and MultiPL-E
- Alignment and Instruction Following: High scores in Arena-Hard and WritingBench
- Agentic Tasks: Robust tool-calling and workflow execution capabilities
In several evaluations, the model performs on par with models exceeding 200 billion parameters, demonstrating the effectiveness of its architecture.
Deployment and Inference
Qwen3-Next-80B-A3B-Instruct integrates seamlessly with modern inference frameworks:
- vLLM for high-throughput, memory-efficient serving
- SGLang for OpenAI-compatible API deployment
- Transformers (latest version) for experimentation and fine-tuning
The model supports tensor parallelism and is optimized for multi-GPU environments, making it suitable for both research labs and enterprise-scale deployments.
Agentic and Tool-Calling Capabilities
The model excels in agentic use cases, particularly when paired with Qwen-Agent, which simplifies tool integration and function calling. This enables developers to build AI agents capable of:
- Calling APIs
- Executing code
- Fetching real-time data
- Managing multi-step workflows
These features make Qwen3-Next-80B-A3B-Instruct an excellent choice for autonomous AI systems and enterprise automation.
Use Cases and Applications
Qwen3-Next-80B-A3B-Instruct is well-suited for a wide range of applications, including:
- Conversational AI and chatbots
- Long-form content generation
- Enterprise knowledge assistants
- Software development and code analysis
- Research and academic analysis
- AI agents and workflow automation
Its balance of performance, efficiency, and scalability makes it a versatile solution for modern AI needs.
Conclusion
Qwen3-Next-80B-A3B-Instruct represents a major milestone in the evolution of open-source large language models. By combining an 80B-parameter backbone with a highly efficient activation strategy, hybrid attention, and ultra-long context support, it delivers exceptional performance at a significantly reduced cost.
For organizations and developers seeking a powerful, scalable, and production-ready language model, Qwen3-Next-80B-A3B-Instruct offers a compelling alternative to traditional dense models. Its architecture not only reflects the future direction of LLM development but also makes advanced AI capabilities more accessible than ever before.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Gemma-3-1B-IT: Google’s Lightweight Multimodal Open-Source Language Model Explained
- LangChain: The Ultimate Framework for Building Reliable LLM and AI Agent Applications
- Dolphin 2.9.1 Yi 1.5 34B : A Complete Technical and Practical Overview
- GLM-4.7: A New Benchmark in Agentic Coding, Reasoning and Tool-Driven AI
- Llama-3.2-1B-Instruct: A Compact, Multilingual and Efficient Open Language Model
3 thoughts on “Qwen3-Next-80B-A3B-Instruct: A Breakthrough in Efficient Large Language Models”