The field of artificial intelligence has witnessed a remarkable evolution and at the heart of this transformation lies the Transformer architecture. Introduced by Vaswani et al. in 2017, the paper “Attention Is All You Need” redefined the foundations of natural language processing (NLP) and sequence modeling. Unlike its predecessors – recurrent and convolutional neural networks, the Transformer model relies entirely on the self-attention mechanism eliminating the need for recurrence and convolution. This innovation led to breakthroughs in translation, text generation and even multimodal AI systems like GPT, BERT and Stable Diffusion.
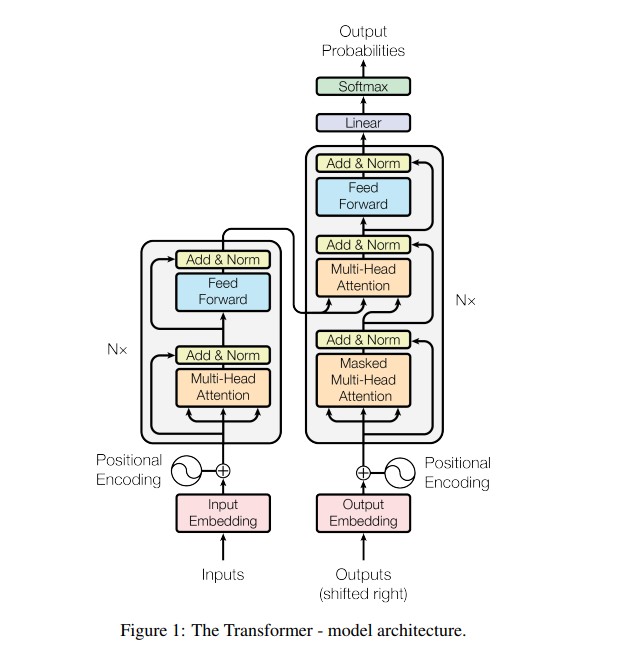
This blog explores the core ideas behind the Transformer, its key components, advantages over previous architectures and its impact on modern AI applications.
Background: The Limitations of Earlier Models
Before the Transformer, most sequence transduction tasks, such as machine translation were powered by recurrent neural networks (RNNs) and their variants – Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU). These models processed data sequentially which made training slower and less efficient especially for long sequences. Although attention mechanisms were later added to improve performance, the core structure still depended on step-by-step computation.
Convolutional neural networks (CNNs) offered parallelization but struggled to capture long-range dependencies efficiently. The computational cost grew with the distance between input and output tokens, limiting scalability. These constraints created a need for a model that could process sequences in parallel while maintaining contextual understanding.
The Birth of the Transformer
The Transformer was proposed as a novel solution that removed the reliance on sequential computation entirely. It introduced the concept of self-attention, a mechanism allowing each word in a sentence to directly attend to every other word. This design not only accelerated training but also improved the model’s ability to learn long-term dependencies.
At its core, the Transformer follows an encoder-decoder architecture. The encoder reads the input sequence and converts it into context-aware representations. The decoder then uses these representations to generate the output sequence, one token at a time. What makes this process powerful is the use of multi-head self-attention which enables the model to focus on different parts of the sentence simultaneously.
Understanding the Attention Mechanism
Scaled Dot-Product Attention
The attention mechanism can be thought of as a way to measure relationships between words. It works using three key components – queries (Q), keys (K), and values (V). Each word in the sequence is transformed into these vectors. The similarity between a query and key determines how much “attention” the model should pay to a particular word.
The output is a weighted sum of the values where weights are determined by a softmax function applied to the dot product of queries and keys scaled by the square root of their dimension. This scaling ensures stable gradients during training.
Multi-Head Attention
Instead of using a single attention function, the Transformer uses multiple attention heads. Each head learns to focus on different aspects of the sentence such as syntax, semantics or positional relationships. The outputs of these heads are then concatenated and linearly transformed. This parallel processing allows the model to capture rich contextual information more effectively.
Positional Encoding: Adding Order to the Sequence
Since the Transformer does not process words sequentially, it lacks an inherent understanding of word order. To address this, Vaswani et al. introduced positional encoding, a mathematical method to represent the position of each token in a sequence. Using sine and cosine functions of different frequencies, the model learns to differentiate between words based on their positions enabling it to understand context while processing all tokens simultaneously.
Why Self-Attention Works Better ?
Self-attention offers several advantages over traditional RNNs and CNNs:
- Parallelization: The Transformer can process entire sequences at once, drastically reducing training time.
- Global Context: Each token can attend to every other token capturing long-range dependencies more efficiently.
- Scalability: It performs well on large datasets and complex tasks without significant computational overhead.
- Interpretability: Visualization of attention weights helps researchers understand how the model learns relationships between words.
Because of these benefits, the Transformer achieves superior performance on benchmark tasks while requiring less training time compared to RNN-based architectures.
Training the Transformer
The original Transformer was trained on large machine translation datasets – English-to-German and English-to-French using the Adam optimizer. The learning rate was dynamically adjusted with a “warmup” schedule, allowing stable convergence. Regularization techniques like dropout and label smoothing were applied to prevent overfitting. The model achieved record-breaking BLEU scores (28.4 for English-German and 41.8 for English-French) surpassing all previous state-of-the-art models.
Real-World Applications and Impact
Since its introduction, the Transformer has become the backbone of modern AI. Models such as BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer) and T5 (Text-to-Text Transfer Transformer) are all based on its architecture. Beyond language processing, Transformers now power computer vision, audio generation, code synthesis and multimodal systems.
In essence, the Transformer’s attention-based approach has made deep learning models more flexible, faster and scalable across domains. Its influence continues to expand into areas like reinforcement learning and scientific computing.
Conclusion
The introduction of the Transformer marked a turning point in artificial intelligence. By removing recurrence and convolution and relying solely on attention mechanisms, Vaswani et al. created a model that is faster, more efficient, and more powerful. Today, every major advancement in NLP and generative AI traces its roots back to this architecture.
As research progresses, new variants like Vision Transformers (ViT), Swin Transformers and hybrid models continue to push the boundaries of what attention-based systems can achieve. Indeed, “Attention Is All You Need” remains not just a paper title but a philosophy that defines the future of AI.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Concerto: How Joint 2D-3D Self-Supervised Learning Is Redefining Spatial Intelligence
- Pico-Banana-400K: The Breakthrough Dataset Advancing Text-Guided Image Editing
- PokeeResearch: Advancing Deep Research with AI and Web-Integrated Intelligence
- DeepAgent: A New Era of General AI Reasoning and Scalable Tool-Use Intelligence
- Generative AI for Beginners: A Complete Guide to Microsoft’s Free Course
3 thoughts on “The Transformer Architecture: How Attention Revolutionized Deep Learning”