

Introduction to SVM
Support Vector Machine (SVM) is a type of supervised machine learning algorithm used primarily for classification tasks though it can also be used for regression. It works by finding a decision boundary called a hyperplane that best separates the data into different classes.
Think of it as a smart line-drawer that aims to split data into distinct categories with the widest margin possible.
Real-Life Analogy: Apples vs Oranges
Imagine you have a basket of fruits containing apples and oranges. You want to build a machine learning model that can automatically classify a fruit as either an apple or an orange based on its features like color, weight and texture.
Support Vector Machine will analyze the data points and draw a line that best separates apples from oranges. The goal? Find the line (or boundary) where the distance from the nearest apple and the nearest orange is maximum.
This is what makes Support Vector Machine so powerful and accurate, it doesn’t just split the data; it splits it confidently.
How SVM Works – The Intuition
At its core, SVM is about maximizing the margin between classes.
- Each data point is plotted in a high-dimensional space.
- The algorithm searches for the best hyperplane that separates the classes.
- The points that lie closest to this hyperplane are called support vectors.
These support vectors influence the position and orientation of the hyperplane.

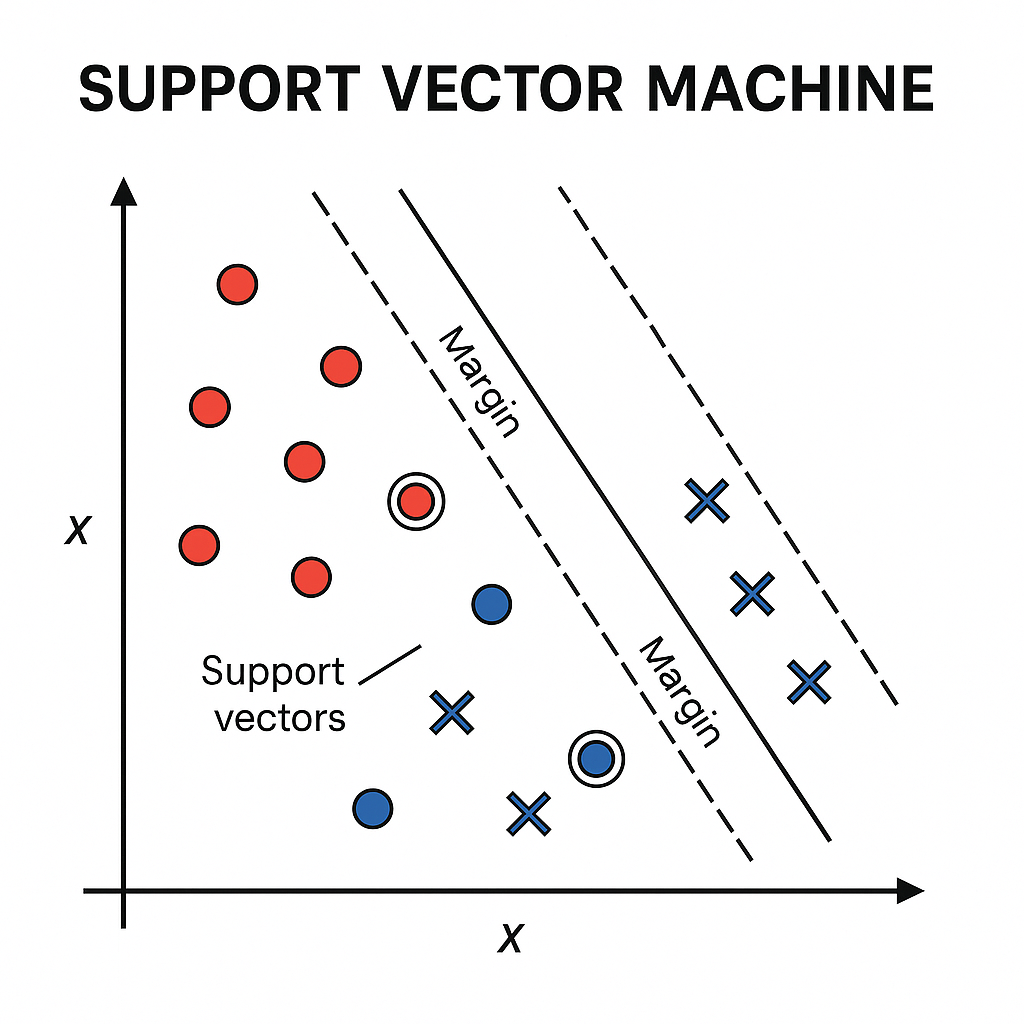
What Are Support Vectors?
Support vectors are the data points that lie closest to the decision boundary. They are the most important points in the dataset because they directly impact how the hyperplane is positioned.
If you removed a support vector, the boundary would shift. That’s why they’re called “support” vectors , they support the margin.
What is a Hyperplane?
A hyperplane is a fancy term for a decision boundary.
- In 2D space, it’s a line.
- In 3D space, it’s a plane.
- In higher dimensions, it becomes a hyperplane.
SVM tries to maximize the distance between this hyperplane and the nearest data points from each class.
Linear vs Non-Linear SVM
Linear SVM works when the data is linearly separable meaning you can draw a straight line between the classes.
But in real life, data is often messy.
- Example: Think of a dataset where class A forms a circle and class B forms a ring around it.
- A straight line won’t help. Enter Non-Linear SVM.
This is where kernels come in.
What is the Kernel Trick?
The kernel trick is a mathematical technique used to transform the data into a higher-dimensional space so that it becomes linearly separable.
Example:
- Original space: Circle inside a ring → not linearly separable.
- After applying a kernel: The data now becomes separable with a plane!
Popular kernel functions include:
- Linear Kernel
- Polynomial Kernel
- RBF (Radial Basis Function) Kernel
- Sigmoid Kernel
Kernels make Support Vector Machine super flexible.
Use Cases of SVM in the Real World
| Industry | Use Case |
|---|---|
| Spam detection | |
| 📝 Education | Handwriting recognition |
| 🛡️ Security | Intrusion detection systems |
| 🛍️ E-commerce | Customer review sentiment analysis |
| 🏦 Finance | Fraud detection |
Support Vector Machine is used whenever high accuracy and clear decision boundaries are important.
Pros and Cons of SVM
Pros:
- Excellent performance for clear margin separation
- Effective in high-dimensional spaces
- Memory efficient (only uses support vectors)
- Can handle non-linear data with kernel trick
Cons:
- Slow with large datasets
- Struggles with overlapping classes
- Choosing the right kernel and parameters is tricky
Conclusion: Is SVM Right for You?
Support Vector Machine is a fantastic algorithm to add to your machine learning toolbox. It’s especially useful when:
- You have clean, structured data.
- Your dataset is not too large.
- You want high accuracy in classification tasks.
If you’re working on problems like email filtering, face detection or financial fraud, Support Vector Machine could be your best bet.