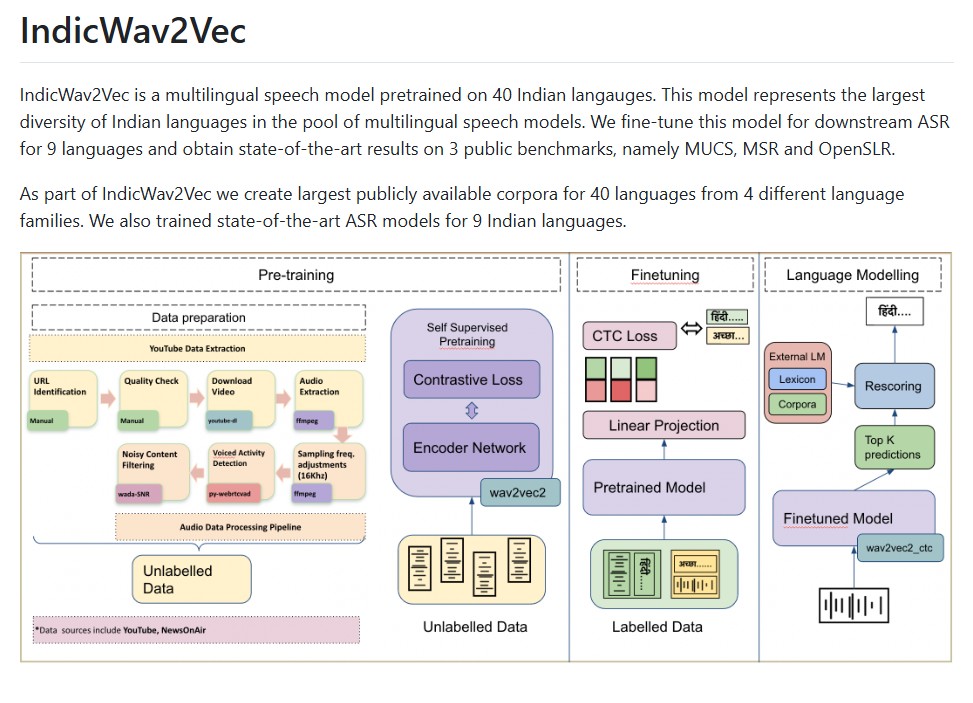
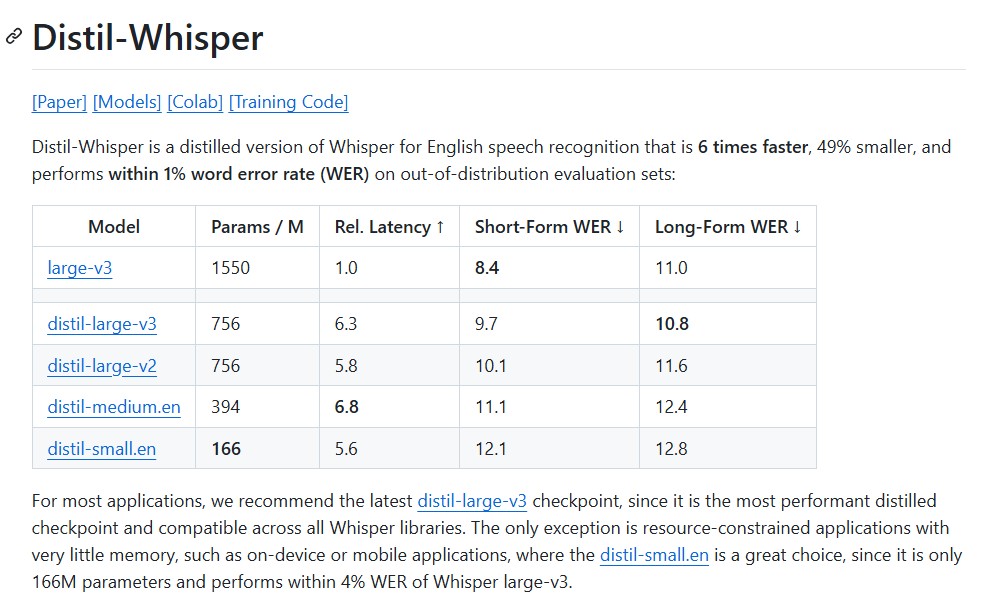
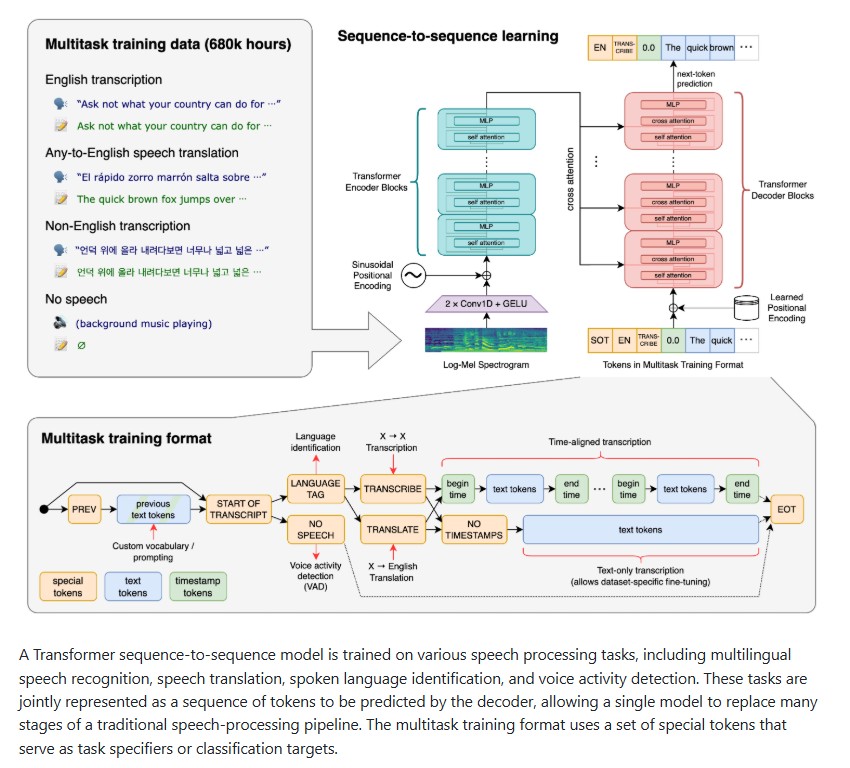
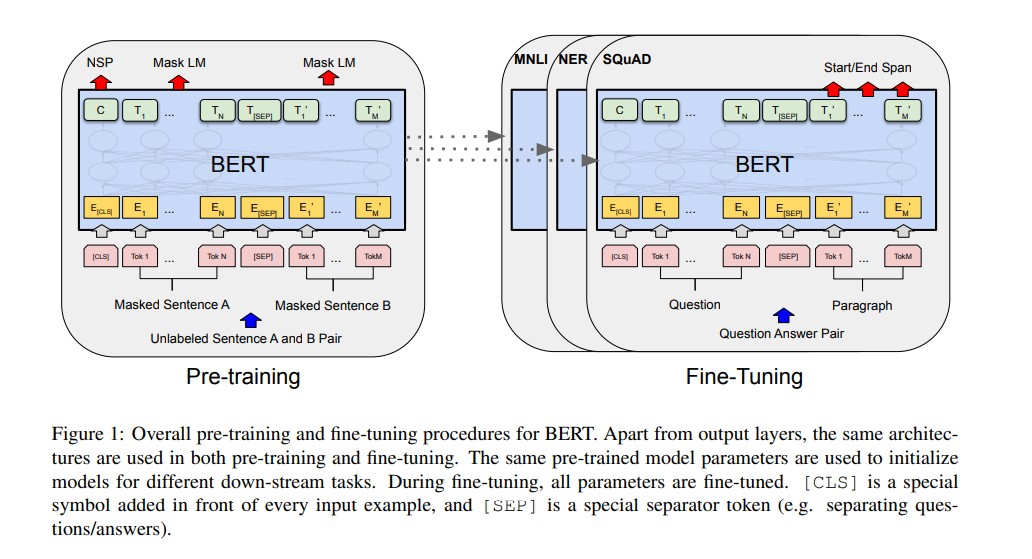
How to Run and Fine-Tune Kimi K2 Thinking Locally with Unsloth

The demand for efficient and powerful large language models (LLMs) continues to rise as developers and researchers seek new ways to optimize reasoning, coding, and conversational AI performance. One of the most impressive open-source AI systems available today is Kimi K2 Thinking, created by Moonshot AI. Through collaboration with Unsloth, users can now fine-tune and … Read more