In the age of large language models (LLMs) and vision-language models (VLMs), handling long and complex textual data efficiently remains a massive challenge. Traditional models struggle with processing extended contexts because the computational cost increases quadratically with sequence length. To overcome this, researchers from DeepSeek-AI have introduced a groundbreaking approach – DeepSeek-OCR, a model that leverages the visual modality as a medium for text compression.
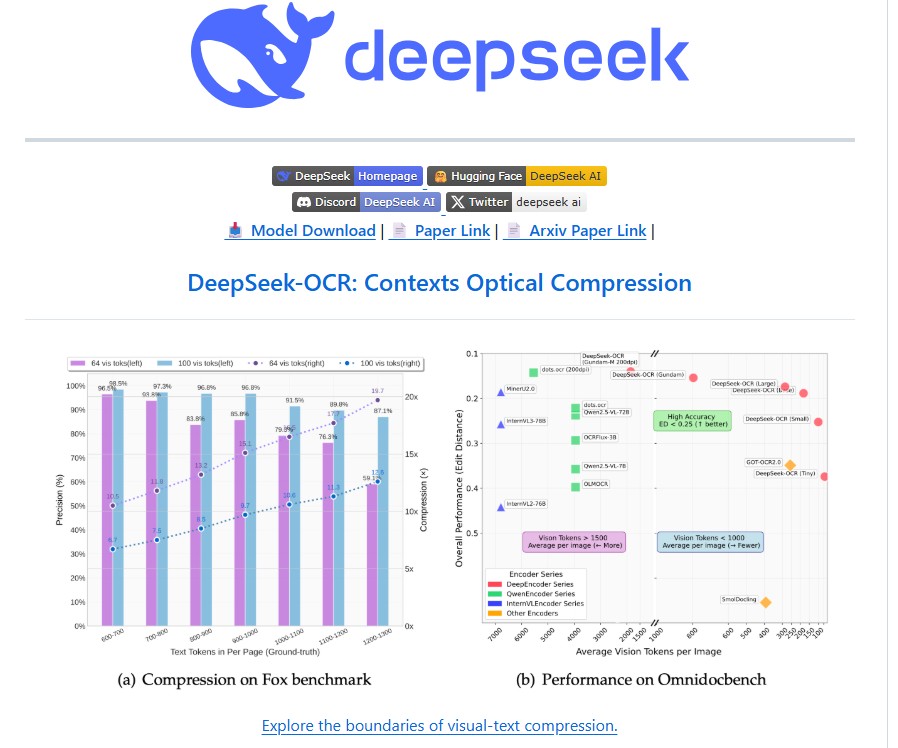
The idea behind DeepSeek-OCR is revolutionary: instead of processing long sequences of text directly, it converts textual content into high-resolution visual representations. This allows models to handle information using far fewer tokens, drastically reducing computational overhead without sacrificing accuracy. With over 96% precision at 10× compression and 60% accuracy even at 20× compression, DeepSeek-OCR sets a new benchmark in context optimization and document understanding.
The Challenge: Long Contexts in Language Models
Large Language Models like GPT-4 or Gemini excel in natural language understanding but face bottlenecks when the input length becomes extremely large such as parsing multi-page documents, PDFs or research papers. The token explosion problem makes it difficult to maintain efficiency.
DeepSeek-AI’s insight was to treat text as images compressing thousands of textual tokens into compact “vision tokens.” This optical context compression approach bridges the gap between visual and linguistic representations, opening the door to a new era of hybrid multimodal AI.
The Innovation: DeepSeek-OCR Architecture
DeepSeek-OCR introduces a novel architecture built on two main components – DeepEncoder and DeepSeek-3B-MoE Decoder.
- DeepEncoder
Acting as the core engine, DeepEncoder processes high-resolution document images while maintaining low memory activation. It uses a combination of window attention, global attention and a 16× convolutional compressor to reduce visual tokens efficiently. This allows the system to achieve extremely high compression ratios while retaining textual clarity. - DeepSeek-3B-MoE Decoder
The decoder reconstructs text from compressed vision tokens using a Mixture-of-Experts (MoE) approach. With only 570M activated parameters, it achieves the expressive capability of a 3B-parameter model while maintaining efficiency equivalent to smaller architectures.
This synergy enables end-to-end OCR transforming visual document inputs directly into structured, readable text without needing separate detection and recognition models.
Key Features and Capabilities
- High Compression Efficiency: DeepSeek-OCR can compress 1,000 text tokens into fewer than 100 vision tokens while achieving 97% accuracy representing a 10× optical compression ratio.
- Scalable Performance: It supports multiple resolutions – Tiny, Small, Base, Large and Gundam modes—allowing flexibility across various document types, from books to newspapers.
- Multilingual OCR Support: Trained on over 30 million multilingual pages, DeepSeek-OCR recognizes nearly 100 languages, including English, Chinese, Arabic and Sinhala.
- Deep Parsing Ability: Beyond basic OCR, the model can extract structured information from charts, formulas and geometry producing outputs in formats like HTML or SMILES.
- General Vision Understanding: Thanks to partial CLIP pretraining, it can describe natural images, detect objects and perform grounding tasks enhancing its versatility.
- Massive Data Throughput: In production, the system can generate up to 200,000+ pages of high-quality training data per day on a single A100-40G GPU, making it invaluable for large-scale pretraining pipelines.
Performance Benchmarks
In comparative evaluations, DeepSeek-OCR outperformed leading models such as GOT-OCR2.0, MinerU2.0, and SmolDocling on the OmniDocBench dataset. While GOT-OCR2.0 required 256 tokens per page, DeepSeek-OCR achieved superior results using just 100 vision tokens. Even with complex layouts like financial reports and academic papers, it achieved state-of-the-art accuracy with fewer computational resources.
For context:
- At 10× compression, DeepSeek-OCR maintained 97% decoding accuracy.
- At 20× compression, it still retained about 60% accuracy, showing robust performance even under extreme compression scenarios.
Applications and Real-World Value
DeepSeek-OCR isn’t just a research concept – it’s a practical tool for scalable AI applications:
- Enterprise Document Processing: Efficiently parse invoices, contracts, and reports.
- Historical Document Digitization: Process large archives with minimal computational cost.
- AI Data Generation: Produce massive synthetic OCR data for LLM pretraining.
- Multimodal Learning: Enable context-aware document reasoning, combining visual and textual insights.
- Education and Research: Assist in parsing academic papers, charts and diagrams with structured outputs.
Its optical context compression method also hints at future breakthroughs in memory-efficient LLMs, where past conversations or documents could be compressed into images to mimic human-like memory decay preserving recent context while letting older information fade naturally.
DeepSeek-OCR vs. Traditional OCR Systems
Traditional OCR pipelines often rely on multi-stage processes – text detection, character recognition and layout reconstruction. DeepSeek-OCR simplifies this into a unified end-to-end model significantly reducing latency and complexity.
Compared to older systems:
- It offers 10–20× better efficiency in token usage.
- Reduces GPU memory overhead by compressing visual inputs.
- Maintains state-of-the-art multilingual performance.
- Provides structured output formats suitable for downstream AI tasks.
Conclusion
DeepSeek-OCR represents a paradigm shift in how AI systems perceive and process textual data. By merging computer vision and natural language processing through optical context compression, it offers a scalable, efficient and intelligent approach to document understanding.
This innovation not only enhances the practicality of OCR technology but also sets the stage for the next generation of multimodal AI systems – ones capable of balancing performance, efficiency, and cognitive reasoning. As DeepSeek-AI continues refining this technology, DeepSeek-OCR may well become the foundation for memory-efficient, context-aware LLMs of the future.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- Wan 2.1: Alibaba’s Open-Source Revolution in Video Generation
- Top 30 More Retro Bollywood Diwali Portrait Prompts for Women Using Gemini AI – Part 2
- PaddleOCR-VL: Redefining Multilingual Document Parsing with a 0.9B Vision-Language Model
- NanoChat: The Best ChatGPT That $100 Can Buy
- Unleashing the Power of AI with Open Agent Builder: A Visual Workflow Tool for AI Agents
5 thoughts on “DeepSeek-OCR: Redefining Document Understanding Through Optical Context Compression”