
As artificial intelligence continues to evolve, Large Vision-Language Models (LVLMs) have revolutionized how machines understand and describe the world. These models combine visual perception with natural language understanding to perform tasks such as image captioning, visual question answering and multimodal reasoning. Despite their success, a major problem persists – hallucination. This issue occurs when a model generates text that is linguistically fluent but not supported by visual evidence. For instance, a model may describe an empty countertop as having a “bowl of fruit” simply because it associates kitchens with such objects.
The recent research paper, “Towards Mitigating Hallucinations in Large Vision-Language Models by Refining Textual Embeddings,” addresses this persistent challenge by proposing a novel method called VisAlign. This approach focuses on refining textual embeddings to ensure that LVLMs use visual information more effectively, leading to more accurate and grounded predictions.
Understanding the Problem: Hallucinations in LVLMs
Hallucinations in AI occur when models rely too heavily on language patterns rather than the visual input provided. LVLMs often generate descriptions or answers that sound reasonable but are not factually grounded in the image or video. For example, a model might misinterpret a blue car as red or claim that a person is jumping when they are simply standing still.
The root of this problem lies in the imbalance between textual and visual modalities. Most LVLMs integrate visual data by appending visual embeddings (image features) to the textual input of a pre-trained large language model (LLM). While this allows easy fusion of visual and textual information, it also introduces a bias toward language, as the backbone LLM was originally trained only on text. As a result, during fine-tuning, the model tends to rely on linguistic cues more than visual ones, which leads to hallucinated outputs.
The Proposed Solution: VisAlign
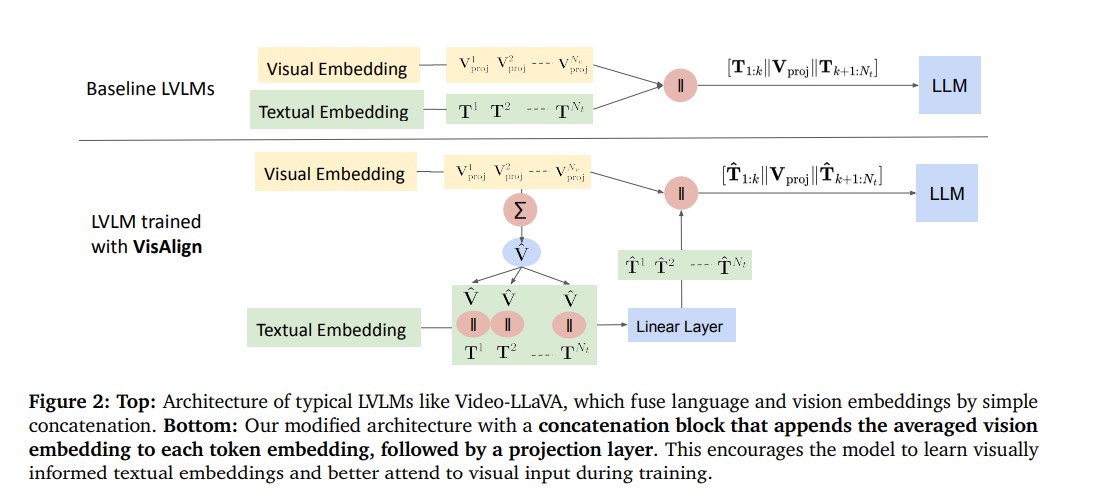
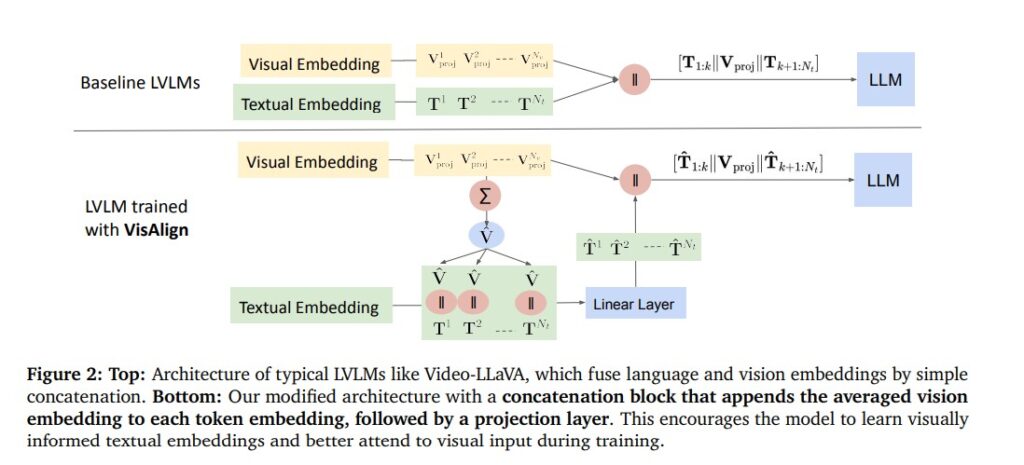
To combat this imbalance, the researchers introduced VisAlign, a simple yet powerful method that refines textual embeddings by integrating visual context before feeding them into the LLM. Unlike previous methods that modify architectures or rely on post-hoc corrections, VisAlign works at the representation level making the model inherently more grounded and balanced.
How VisAlign Works
The process begins with extracting visual embeddings using a frozen visual encoder. Instead of simply attaching these embeddings to textual tokens, VisAlign applies average pooling to create a summarized visual representation. This representation is then merged with each textual embedding, producing visually informed text tokens.
These fused embeddings are passed through a projection layer that maps them back into the original LLM space, ensuring smooth integration. The resulting model receives inputs where every textual token carries both linguistic and visual information leading to more balanced attention across modalities.
By refining how the model attends to visual versus textual cues, VisAlign ensures that descriptions are grounded in visual evidence effectively reducing hallucinations.
Experimental Evaluation
The researchers evaluated VisAlign on several standard hallucination benchmarks, including MMVP-MLLM, POPE, MERLIN, Mementos and HallusionBench. Across all datasets, VisAlign consistently improved accuracy and reduced hallucinations compared to baseline models.
Key Results
- MMVP-MLLM Benchmark:
VisAlign improved performance by 9.33%, showing stronger grounding in visual evidence. - POPE Benchmark:
Achieved a 2.99% accuracy increase and higher precision, meaning fewer hallucinated objects. - MERLIN and Mementos Benchmarks:
Demonstrated enhanced factual consistency and reduced object and action hallucinations in visual sequences. - HallusionBench:
Improved accuracy by around 3% on difficult tasks involving conflicting visual and textual cues.
These results confirm that refining textual embeddings leads to more faithful, visually consistent reasoning, reducing the tendency of LVLMs to generate factually incorrect outputs.
Why VisAlign Stands Out
Many previous methods for reducing hallucinations in LVLMs rely on post-processing or reinforcement learning techniques. These approaches correct hallucinations after generation or adjust model outputs during inference but they don’t address the root cause – the imbalance between modalities.
VisAlign takes a fundamentally different approach by embedding visual information directly into textual representations during training. This strategy:
- Promotes balanced attention between vision and language.
- Enhances cross-modal reasoning without architectural complexity.
- Improves efficiency since it doesn’t require additional modules or inference-time computation.
Moreover, the study shows that VisAlign can complement other state-of-the-art methods such as Visual Contrastive Decoding (VCD). When combined, both techniques deliver the highest performance, proving that VisAlign is versatile and compatible with existing solutions.
Broader Implications for AI Development
The findings from this study have broader implications for the future of multimodal AI systems. As LVLMs become integral in real-world applications such as autonomous vehicles, healthcare diagnostics and educational tools ensuring factual accuracy and visual grounding becomes critical.
By improving the model’s ability to see what it says, VisAlign not only enhances reliability but also builds trust in AI systems. Reducing hallucinations is not just a technical improvement; it is a crucial step toward safe and responsible AI deployment in domains where accuracy and interpretability are vital.
Conclusion
The research on “Towards Mitigating Hallucinations in Large Vision-Language Models by Refining Textual Embeddings” highlights an important breakthrough in multimodal AI. The proposed VisAlign technique offers a simple yet highly effective way to make LVLMs more visually grounded by integrating visual context directly into textual embeddings.
By achieving better balance between vision and language, VisAlign reduces hallucinations, enhances visual reasoning and improves factual consistency across multiple benchmarks. This advancement moves AI closer to achieving true visual understanding rather than relying on memorized text patterns.
As the demand for reliable multimodal systems grows, approaches like VisAlign will play a pivotal role in shaping the next generation of AI models that are both intelligent and trustworthy.
Follow us for cutting-edge updates in AI & explore the world of LLMs, deep learning, NLP and AI agents with us.
Related Reads
- DeepEyesV2: The Next Leap Toward Agentic Multimodal Intelligence
- Agent-o-rama: The End-to-End Platform Transforming LLM Agent Development
- CALM: Revolutionizing Large Language Models with Continuous Autoregressive Learning
- Supervised Reinforcement Learning: A New Era of Step-Wise Reasoning in AI
- Context Engineering 2.0: Redefining Human–Machine Understanding
2 thoughts on “Reducing Hallucinations in Vision-Language Models: A Step Forward with VisAlign”